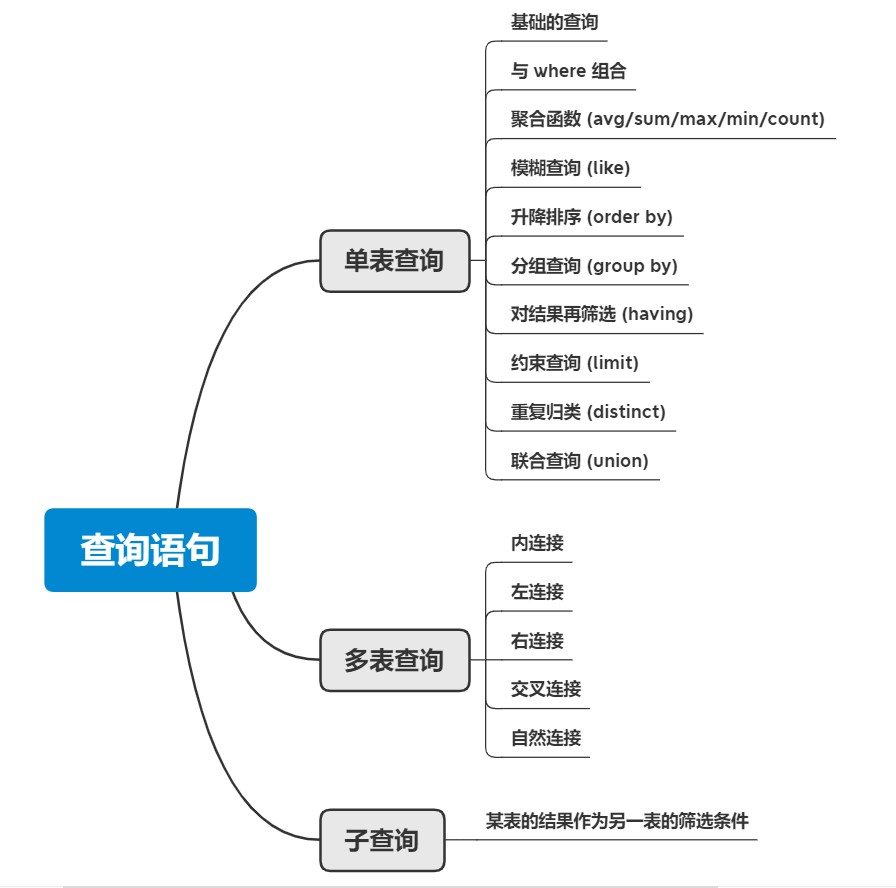
QueryStatement
MySQL 的查询语句
学习笔记,仅供参考
思维导图:
在之前的数据操作中就已经知道想要查询数据可以使用 select 来查询数据信息。但那仅仅是基本的查询方式,下面时列举的是在基础之上加入过滤、条件等语句更进一步的精确查询。
🧶 单表查询
select * from t1, t2;// 返回一个笛卡尔积(即返回 t1,t2 数据的所有组合)select 2*7 (from dual);// dual 为默认的伪表select * from <tab_name> where [condition];// where 带条件查询(有: >, <, =, =>, <=, and, or, not …)
与 where 组合的
select * from <tab_name> where <field_name> in (value1, value2, ...);// 等价于 (where field_name = value1 or field_name = value2 or …)select * from <tab_name> where <field_name> between 18 and 20;// 等价于 (where field_name >= 18 and field_name <= 20 )select * from <tab_name> where <field_name> is null;// 查看某字段为 null 的数据
注 : 还可以在关键字前加 null 来查看与条件相反的情况
聚合函数(数据库自带的,用于统计数据)
select sum(math) from score;// 求 math 字段所有数据之和
类似的函数还有:avg(math) - 平均值;max(math) - 最大值;min(math) - 最小值;count(math) - math 列不为 null 的行数。
注意 : count(1), count(*) 和 count(字段) 的区别。 在 InnoDB 引擎中,count(1), count(*) 都是统计数据行数,且`count(*)` 被 MySQL 优化多次,所以它统计也包含 null 的数据; 而 `count(字段)` 只能统计行字段为非 NULL 的行数,因为其要判断数据该字段是否为 NULL,所以在效率上就会低些。
模糊查询(like)
select * from <tab_name> where name like '张%'; ('张_')// 查询名字姓张的数据,%代表一个或多个字符,而_只代表一个字符
像之前查询字符集字符也用到了模糊查询。(show variables like ‘characteset%‘)
升降排序(order by)
select * from <tab_name> order by <field_name>;// 查表根据某字段来排序,默认为升序,字段后加desc表示降序
分组查询(group by)
select avg(age), gender from <tab_name> group by gender;// 按照性别分组,查看男女的平均年龄。
分组查询像是查看统计表一样,必须要有聚合函数,然后按照某字段进行分组,该字段要出现两次且前后相同
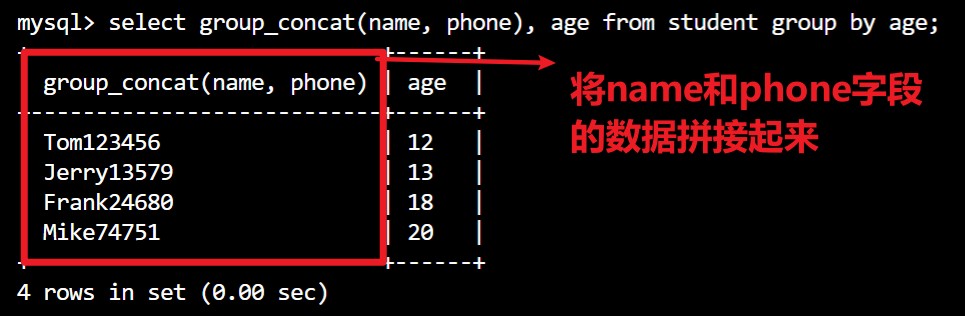
select group_concat(fiedl1, field2, ...), gender from <tab_name> group by gender;// group_concat 能将括号中的字段数据拼接起来显示
对查询结果再筛选(having)
select <field_name> from <tab_name> ... having [condition];// 对查询结果在筛选
示例图如下:
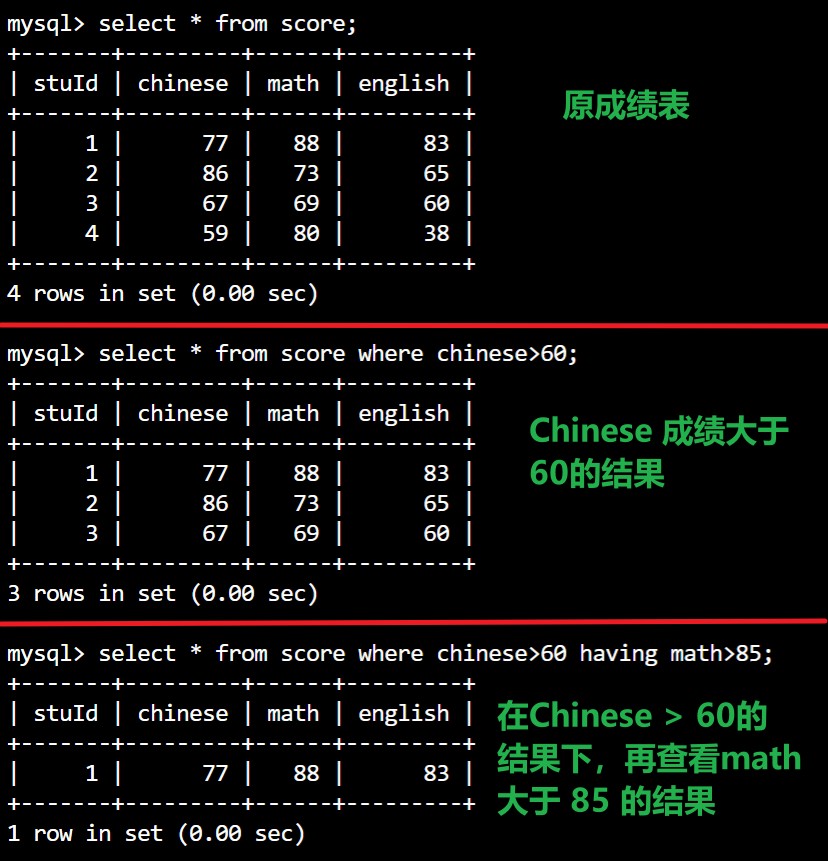
区别 :
where 是对 某表 中的某字段作条件筛选
having 是对 某查询结果(虚拟表) 中的字段再作条件筛选
约束查询(limit)
select * from <tab_name> limit 0,3;// limit 指对结果进行限制,0 表示限制数据的起始下标(类似数组下标), 3 表示偏移量。即这条语句指仅显示前三条数据
重复归类(distinct)
select distinct address from <tab_name>;// distinct 将重复的地区舍去,默认为 all
联合查询(union)
select age, gender from t1 union select age, gender from t2;// 查看两表中的 age, gender
区别 : 两表中所选的字段个数必须一致,类型可以不同
联合查询结果的虚拟表字段以 t1 表所选的字段为准,t2 表所查得的数据接在 t1 数据之后
💎 多表查询
多表查询就是对多张表进行连接查询
内连接
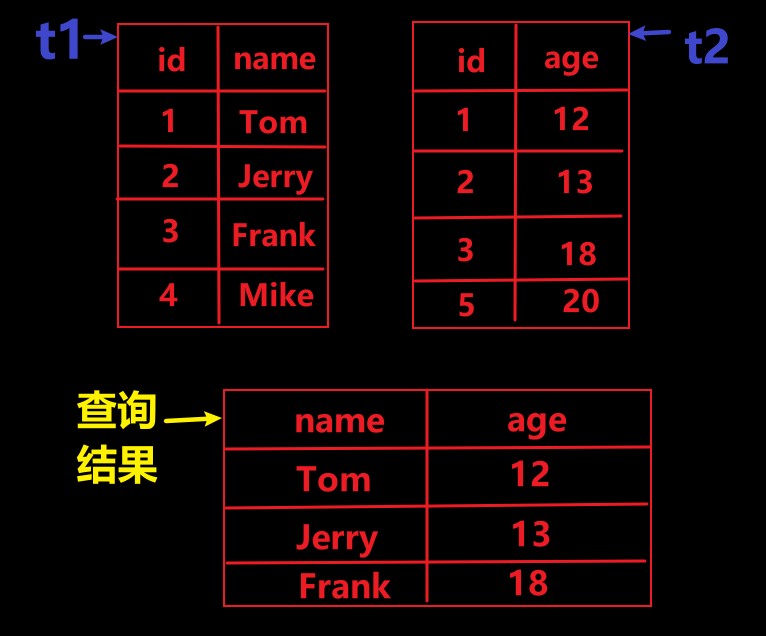
select name, age from t1 inner join t2 on t1.id=t2.id;// 内连接查询
过程 : 就像是先把 t1,t2 拼接在一起,然后通过 t1.id=t2.id 来找到满足条件的数据,再将数据放到所选的对应的字段中。(注:两张表要有公共的列,如:id:1,2,3…)
select <field1>, <field2>, ... from (t1 inner join t2 on t1.id=t2.id) inner join t3 on t1.id=t3.id;// 三表内联查询,将两表内连的结果作为一个表再与其他表内联。
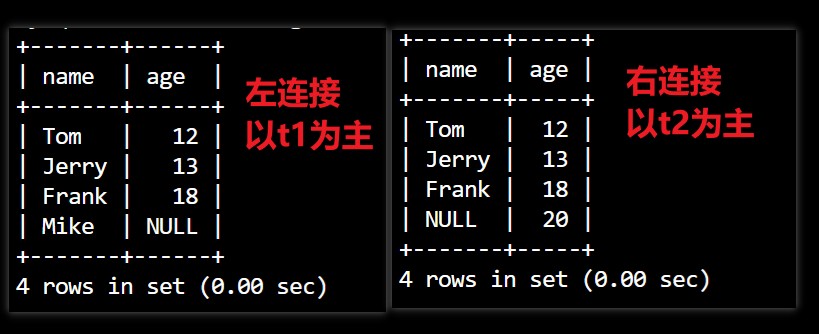
左连接 (left join)
select name, age from t1 left join t2 on t1.id=t2.id;// 左连接,以左表为主,右边没有的用 NULL 补齐
右连接 (right join)
select name, age from t1 right join t2 on t1.id=t2.id;// 右连接,以右表为主,左边没有的用 NULL 补齐
交叉连接 (cross join)
select * from t1 cross join t2; (= select * from t1, t2)// 返回一个笛卡尔积
自然连接 (natural join)
select * from t1 natural join t2;// 相当于内连接,但两表要有相同的字段名(如:t1.id=t2.id),因此不用再加 on 条件。若两表没有相同的字段名(如:t1.id=t2.stuid),则返回笛卡尔积
当然还有 natural left join 和 natural right join。
📃 子查询
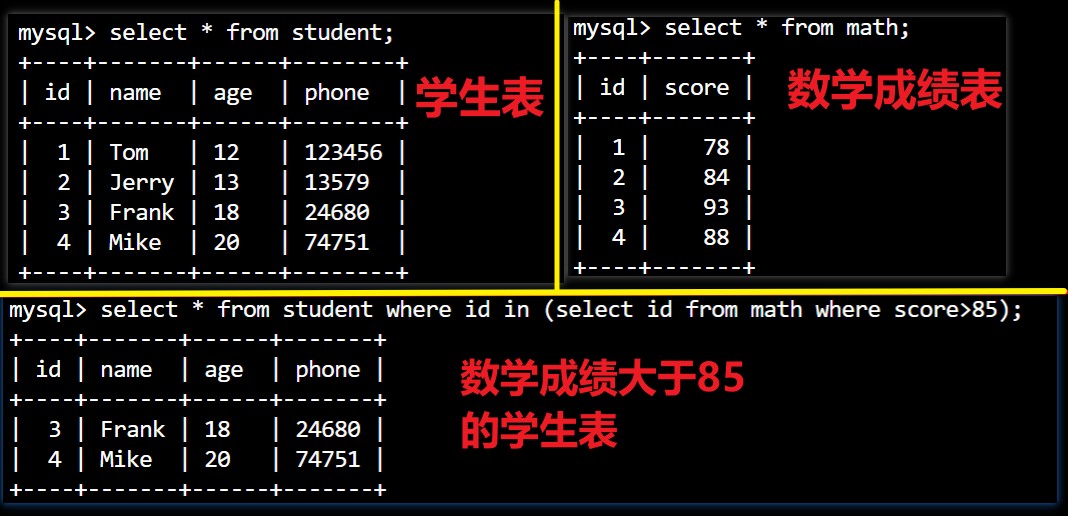
select * from student where id in (select id from math where score>85);// 将某表的结果作为另一个表查询的筛选条件
select * from student where exists (select id from math where score>85);// exists 表示若有一个成绩大于 85 的,就打印所有的学生信息