Collection2
记录 JavaSE 中集合框架之 Iterator、Queue、Map
学习笔记,仅供参考
参考:B站Mirco_Frank - java 进阶 | 官网教程 | JDK-9 API | javatpoint 教程-可供练习
目录
在了解 Queue、Map 之前先把贵人 Iterator 先介绍了,毕竟发达了不能忘了贵人的帮助
🔄 迭代器(Iterator)
字典中迭代指 重复一个过程 (to repeat a process),那么迭代器就是用来迭代的机器,而在 Java 中这种 “机器” 可能指的是某接口、类、方法等。从之前的继承图中可看出贵人 Iterator 是个接口 Iterator<E>,可以让 Collection 的所有类都能使用它的方法来迭代集合的元素,在集合框架中可以称为是 通用光标。
优点 :Collection 的所有类都能用,无论是连续存储的 ArrayList 还是离散存储的 LinkedList;容易完成集合的读取和删除数据操作,而传统的 for 循环则不能较好地对集合元素
缺点 :只能单一方向的迭代集合元素;增删改查中 只能完成删和查,不允许增和改
方法
hasNext()// 判断迭代时是否还有元素,类似于 Scanner 的 hasNext()next()// 返回迭代中的下个元素remove()// 删除最近的迭代元素,也可选择将删除的元素返回// 假设 ArrayList 类型的 list 为 ["Tom", "Jerry", "Frank", "Mike"] /** * 用迭代器来查看集合的元素 */ // 新建迭代器,用集合的 iterator 方法返回一个迭代器 Iterator<String> iterator = list.iterator(); while (iterator.hasNext()) { // get element of list by using next() System.out.print(iterator.next() + " | "); } /* print result: Tom | Jerry | Frank | Mike */ /** * 用迭代器来删除集合的元素 */ Iterator<String> iteratorRm = list.iterator(); while (iteratorRm.hasNext()) { if (iteratorRm.next().equals("Frank")) { iterator.remove(); } } // list: ["Tom", "Jerry", "Mike"]
与 for 循环的区别
在之前遍历数组时,经常会使用 for 循环来遍历完成。而在集合中也可用 for 来遍历,下面就来看看它们的区别
// 假设 ArrayList 类型的 list 为 ["Tom", "Jerry", "Frank", "Mike"]
/**
* 查看元素
*/
System.out.println("===Iterator===");
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
System.out.print(iterator.next() + " | ");
}
System.out.println("===For-i===");
for (int i = 0; i < list.size(); i++) {
System.out.print(list.get(i) + " | ");
}
System.out.println("===For-each===");
for (String value : list) {
System.out.print(value + " | ");
}
/******************************************************/
/**
* 删除元素
*/
System.out.println("===Iterator===");
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
if (iterator.next().equals("Frank")) {
iterator.remove();
}
}
System.out.println("===For-i===");
for (int i = 0; i < list.size(); i++) {
if (list.get(i).equals("Frank")) {
list.remove(i);
}
}
/*******************************************************/
/**
* 修改元素
*/
System.out.println("===For-i===");
for (int i = 0; i < list.size(); i++) {
if (list.get(i).equals("Frank")) {
list.set("Fuck");
}
}从上面代码能可看出三种方法都能完成遍历打印元素,但在之前就已经知道 for-each 不能对操作数据,它的过程相当于依次将数组元素复制出来,无法对真正的数组造成影响
由于迭代器的 hasNext() 做判断,next() 获取元素,remove() 方法删除元素,所以它没法来修改集合。故在集合中,想查看和删除可以用迭代器,而修改和增加还是要用 for-i 循环
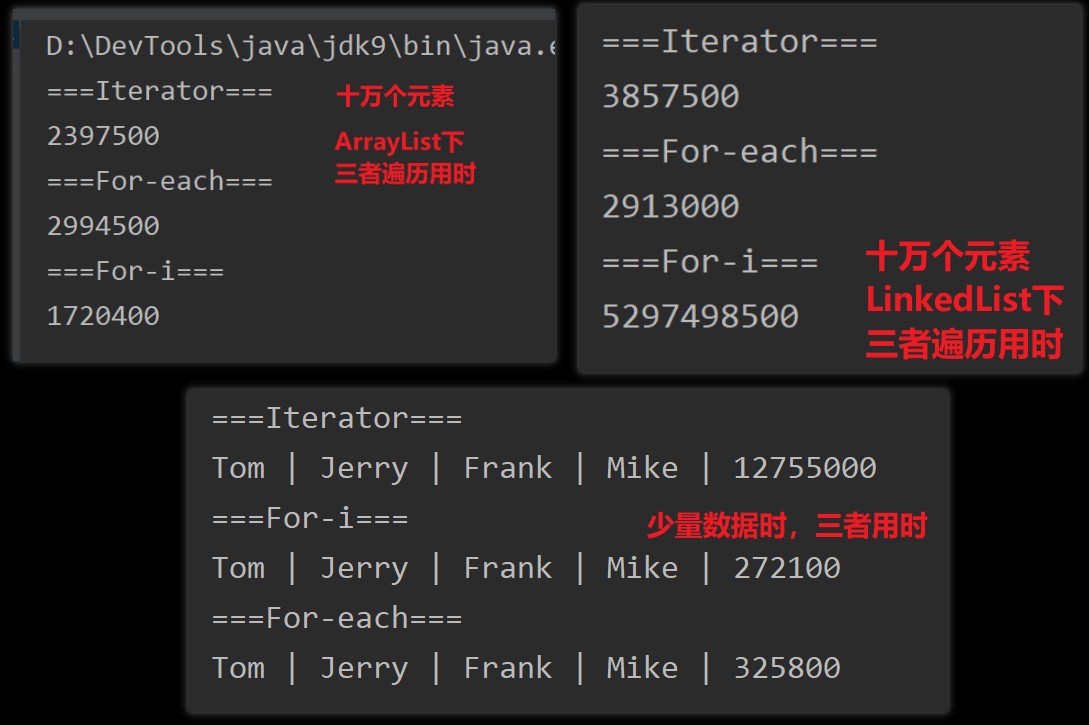
较大数据的情况下,查询数据时三者性能比较,若集合为 ArrayList 这种连续存储的,三者性能相当;若集合为 LinkedList 这种离散存储的,iterator, for-each >> for-i,在测试时明显感觉到 for-i 要等待十几秒
参考 iterator详解以及和for循环的区别 | List遍历:for,foreach Iterator 速度比较
👩🏿🤝🧑🏻 PriorityQueue & Deque
说完贵人后继续回到 Collection 家族上来,接着了解 Queue 的实现类,PriorityQueue 和 Deque。队列主要体现的就是先进先出的思想
先了解 PriorityQueue,与 List 一样也是大小无限制,有序的,但此顺序是根据 自然顺序(如字母或数字大小) 或者构造时所指定的顺序来进行排序。它不允许 null 元素,也不允许插入不可比较 (non-comparable) 的对象
底层上,也是由数组来存储元素,当容量不够时,也能自动扩容。
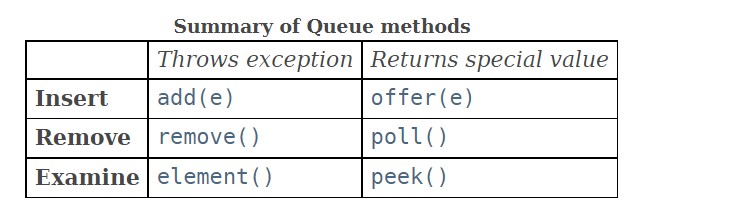
在性能上,入队和出队方法 (offer, poll, remove() 和 add) 是 O(logn) 的时间复杂度;remove(Object) 和 contains(Object) 方法是线性时间复杂度 O(n) ;查询方法 (peek, element, size) 则是常量时间复杂度 O(1)
// 创建 PriorityQueue 对象
PriorityQueue<String> queue = new PriorityQueue<>();
// add element
queue.offer("Tom");
queue.offer("Jerry");
queue.add("Frank");
queue.add("Mike"); // queue: ["Frank", "Mike", "Jerry", "Tom"]
// remove element
queue.remove(); // queue: ["Mike", "Jerry", "Tom"]
queue.poll(); // queue: ["Mike", "Jerry", "Tom"]
// query element
queue.element(); // return: Frank
queue.peek(); // return: Frank
// get size of queue
queue.size(); // return: 4
/*
★ 区别:
1. offer, add 都能添加元素。但当队列满时,offer 返回 false,add 抛异常
2. poll, remove 都能删除队列头元素。同样队列满时,poll 返回 null,remove 抛异常
3. peek, element 都返回但不删除头元素。队满时,peek 返回 null,element 抛异常
*/
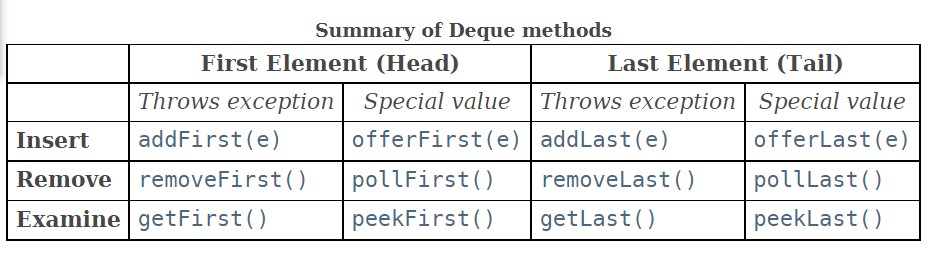
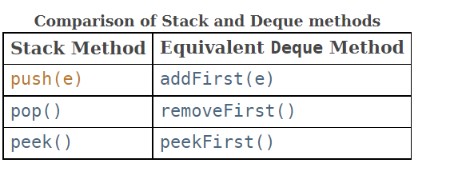
再来看 Deque,它是 Queue 的子接口,全称为 double ended queue 即双向队列,头和尾都能作为操作数据的起始点,实现类有:ArrayQueue,LinkedList 等。同样没有大小的限制,所具有的方法与 PriorityQueue 一样有两种形式,抛异常或返回值(null/false)。如下图所示
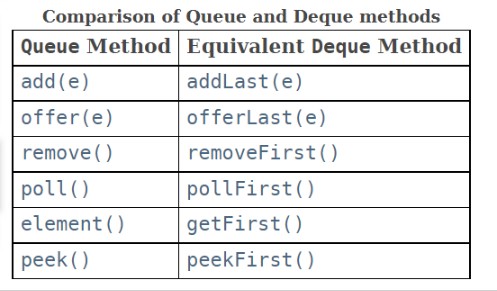
由于双向队列可以正反方向处理数据,所以它也可以降维为单向的队列或者堆栈,这也是为什么 LinkedList 既能作队列又能作堆栈的原因。下面为方法的对照图
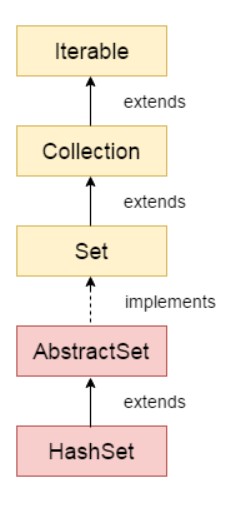
📮 HashSet
HashSet 是 Set 接口下的一个实现类,继承图如下
特点:不重复、无序,允许至多有一个 null ;基本的操作方法 (add, remove, contains, size) 都是 O(1) 的性能
底层:当用构造器创建时实际返回的是 HashMap 的实例,而 HashMap 是 Map 家族的,后面在说。HashMap 的底层则是基于 HashTable(哈希表),它是一种数据结构。在 JKD1.7 前是 数组+链表 的形式,而 JDK1.8 之后是 数组+链表/红黑树。并且 HashSet 的不重复的性质就是由此实现的
元素不重复的原理
先根据元素的哈希值进行分组,然后再通过链表/红黑树存储数据,步骤如下:
根据哈希值分组
对相同的哈希值进行链式存储
若链表上的元素大于 8 个时,转为红黑树存储
由于是根据哈希值分组,所以 HashSet 输出时的顺序也是根据哈希值的顺序而不是插入的顺序。下面通过代码来阐述整个过程
HashSet<String> set = new HashSet<>();
set.add("abc");
set.add("def");
set.add("hello");
set.add("world");
// set: [abc, def, hello, world]
set.add("abc"); // set: [abc, def, hello, world]
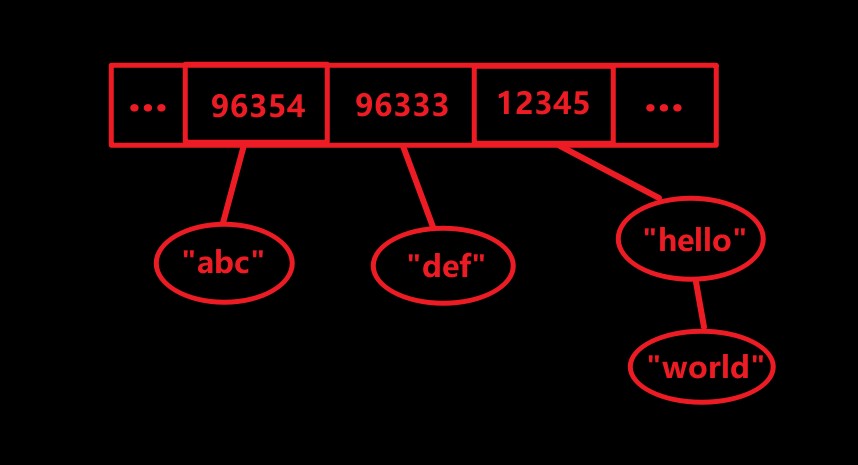
首先创建了 HashSet 对象,然后添加数据。而当 set 调用 add() 时,add 会调用元素的 hashCode() 和 equals() 方法来判断是否重复
添加第一个 “abc” 时,调用 “abc” 的hashCode 获取哈希值为 96354,又集合中没有 96354 这个哈希值元素,故将其添加到集合中
同样添加 “def” 时,也是如此,集合中没有 99333 这个哈希值元素,故添加之
假设 “hello” 和 “world” 具有相同的哈希值 12345,那么当添加 “world” 时,会在集合中找到 12345,然后调用 equals 方法来比较集合中哈希值为 12345 的元素的内容是否与所添加的元素内容相同,不同则链式添加,相同则不再添加
而在添加第二个 “abc” 时,计算的哈希值能够在集合中找到,接着又调用 equals 方法比较出集合中已存在相同的元素,故不在将 “abc” 加入到集合中
方法
方法与之前的用法类似,这里就不再代码示例
add(E e)// 若集合中不存在此元素,将所给元素添加至集合clear()// 清空集合中的元素contains(Object o)// 判断集合中是否存在所给的元素isEmpty()// 判断集合是否为空iterator()// 返回该集合的迭代器remove(Object o)// 若存在则在集合中删除所给元素size()// 返回集合所拥有元素的个数
LinkedHashSet 则是有顺序的 HashSet,它的元素都是按照插入时的顺序来进行排列的,同样也是去重的,允许有 null
🌲 TreeSet
TreeSet 类也是 Set 的一个实现类,与HashSet 不同的是,它是用树来存储数据的。特点上,不重复、自然顺序(升序)、不允许 null。性能上,增删查(add, remove, contains) 都是 O(logn)
特别方法
增删改查等常规的方法就不再记录,下面记录些 TreeSet 特有的方法
ceiling(E e)// 返回集合中大于或等于所给元素的最小值,即稍大于所给值的元素,没有则返回 nullfloor(E e)// 返回集合中小于或等于所给元素的最大值,即稍小于所给值的元素,没有则返回 nullhigher(E e)// 返回集合中严格大于所给元素的最小值,即稍大于所给值的元素,没有则返回 nulllower(E e)// 返回集合中严格小于所给元素的最大值,即稍小于所给值的元素,没有则返回 null// 创建 TreeSet 对象 set TreeSet<String> set = new TreeSet<>(); set.add("Tom"); set.add("Jerry"); set.add("Frank"); System.out.println(set); // 输出 set 为 ["Frank", "Jerry", "Tom"] // 按照字母的升序进行排列 set.ceiling("Mike"); // return: Tom set.floor("Mike"); // return: Jerry set.ceiling("Zero"); // return: null // 对于字符串它是先根据首字符的 ASCII 比大小,若一样在比第二个,依次下去descendingIterator()// 返回降序形式的迭代器descendingSet()// 返回此集合的反序集合,该反序集合类型为NavigableSet词典意思为可导航、可航行,继承自 SortedSet 应该是能进行排序// 假设集合 set 为 [Frank, Jerry, Tom] Iterator iterator = set.descendingIterator(); // 迭代输出为:Tom, Jerry, Frank // 正好与 set 的排序相反,即降序 NavigableSet<String> reverseSet = set.descendingSet(); System.out.print(reverseSet); // 打印反序集合为:[Tom, Jerry, Frank]first()// 返回此集合的第一个元素,及最小的last()// 返回此集合的最后一个元素,及最大的headSet(E toElement)// 将集合中那些 严格小于 所给元素的元素组成一个小集合并返回,返回集合的类型为SortedSetheadSet(E toElement, boolean inclusive)// 将集合中那些 小于或等于 (inclusive is true) 所给元素的元素组成一个小集合并返回,返回集合的类型为NavigableSettailSet(E toElement)// 将集合中那些 大于或等于 所给元素的元素组成一个小集合并返回,返回集合的类型为SortedSettailSet(E toElement, boolean inclusive)// 将集合中那些 大于或等于 (inclusive is true) 所给元素的元素组成一个小集合并返回,返回集合的类型为NavigableSetsubSet(E fromElement, E toElement)// 将集合中那些在 [fromElement, toElement) 所给元素的元素组成一个小集合并返回,返回集合的类型为SortedSetsubSet(E fromElement, boolean inclusive, E toElement, boolean inclusive)// 将集合中那些 fromElement, toElement 所给元素的元素组成一个小集合并返回,返回集合的类型为NavigableSet// 假设集合 set 为 [Frank, Jerry, Tom] SortedSet<String> sortedSet = set.headSet("Jerry"); NavigableSet<String> navigableSet = set.headSet("Jerry", true); System.out.println(set); // set: [Frank, Jerry, Tom] /*======headSet======*/ System.out.println(sortedSet); // sortedSet: [Frank] System.out.println(navigableSet); // navigableSet: [Frank, Jerry] /*======tailSet======*/ System.out.println(set.tailSet("Jerry")); // result: [Jerry, Tom] System.out.println(set.tailSet("Jerry", false)); // result: [Tom] /*======tailSet======*/ System.out.println(set.subSet("Frank", "Tom")); // return: [Frank, Jerry] System.out.println(set.subSet("Frank", false, "Tom", false)); // return: [Jerry]pollFirst()// 查找并删除第一个元素,即最小的,集合为空则返回 nullpollLast()// 查找并删除最后一个元素,即最大的,集合为空则返回 null
📅 Map
Map<key, value> 接口,一种表示键值映射的对象,不能有重复的键且每个键至多映射一个值。一个图的内容可有三个角度观察:键集合、值集合和键值映射集合。顺序为迭代器返回元素的顺序,而 TreeMap 能够制定自己的顺序。
一些图的实现对键和值有一定的约束,如有的禁止空键和空值;有的对键的类型有约束。想要插入一个不合法的键或值则会抛出非检查时异常,特别是 NullPointerException 或 ClassCastException;想查询一个不合法的键或值可能会抛出异常或返回 false。
Map 不能够遍历,故要用 keySet() - 键集合视图 或 entrySet() - 键值映射集合视图 方法将其变为 Set 后在做遍历
三个子类:HashMap(无序)、TreeMap(保持降序) 和 LinkedMap(保持插入顺序)
下例简要展示如何创建及遍历 Map
public class Test1 {
public static void main(String[] args) {
// 非泛型 Map (Old style)
Map map = New HashMap(); // 创建 map
// 添加键值对
map.put(1, "Tom");
map.put(2, "Jerry");
map.put(5, "Frank");
map.put(3, "Puck");
// 转为集合,以便用迭代器遍历
Set set = map.entrySet();
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
// 将获取的元素转为 Map.Entry,能够分开取键和值
Map.Entry entry = (Map.Entry) iterator.next();
System.out.println(entry.getKey() + ":" + entry.getValue());
}
}
}
/*
print result:
1:Tom
2:Jerry
3:Puck
5:Frank
*/
public class Test2 {
public static void main(String[] args) {
// 使用泛型 Map (New Style)
Map<Integer, String> map = HashMap<>();
map.put(2, "Tom");
map.put(3, "Frank");
map.put(1, "Jerry");
// for-each 遍历元素
for (Map.Entry entry : map.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}
}
}
/*
print result:
1:Jerry
2:Tom
3:Frank
*/
// 在 Java 1.8 之后,通过新特性能够更加方便地进行遍历
public class Test3 {
public static void main(String[] args) {
Map<Integer, String> map = HashMap<>();
map.put(2, "Jerry");
map.put(3, "Frank");
map.put(1, "Tom");
// 先返回该map的集合视图
map.entrySet()
.stream() // 返回该集合的顺序流
.sorted(Map.Entry.comparingByKey()) // 根据所提供的比较器来进行排序
.foreach(System.out::println); // 用 for-each 新特性进行遍历
}
}
// Note:其中比较器还能用 comparingByValue() 来由值来排序
// 用 comparingByKey(Comparator.reverseOrder()) 降序排列
/*
print result:
1:Jerry
2:Tom
3:Frank
*/常规方法
cleaer()// 移除该 map 所有的映射containsKey()、containsValue()// 判断 map 中是否包含制定的键或值,是返回 truestatic Map.Entry entry(K k, V v)// 静态方法,返回一个不可变的 Map.Entry,且包含所给的键值static Map of(K k1, V v1)// 静态方法,返回一个不可变的 Map,其中该 map 包含所给的键值;该方法重载是从无参到给十个键值对equals(Object o)// 比较该 map 与指定的对象是否元素相同get(Object key)// 获取指定键对应的值,若没有该键则返回 nullisEmpty()// 判断该 map 是否为空put(K k, V v)// 添加一对键值,若输入的键已有值,则该值将被替换为所给的值putAll(Map m)// 将所给 m 的元素复制给此 mapputIfAbsent(K k, V v)// 当 map 中不存在所给键时,才将所给键值对添加到图中,且返回 nullpublic class Test { public static void main(String[] args) { Map<Integer, String> map = HashMap<>(); map.put(1, "Tom"); // 1 -> Tom s map.put(1, "Jerry"); // 1 -> Jerry map.putIfAbsent(1, "Frank"); // 1 -> Jerry } } /* Different put(): 无论map有无该键都会添加所给键值对 putIfAbsent(): 先判断map是否有该键,有则返回原有的值;无则添加所给键值对并返回 null */remove(Object k)// 删除指定的键的映射,并返该键所映射的值;无该键则返回 nullremove(K k, V v)// 删除 map 中包含的指定的键值,成功返回 true;失败返回 falsereplace(K k, V v)// 将 map 中的键所映射的值替换为所给的值,并将原值返回;若不存在所给键则返回 nullreplace(K k, V oldV, V newV)// 将 map 中的映射替换为指定的键值对,成功为 true,反之 falsesize()// 返回 map 的大小values()// 返回 Collection 值集合视图
🔋 HashMap, LinkedMap, TreeMap
HashMap 实现类,特点有:没有重复键、允许有一个 null 键和多个 null 值、不能保证顺序、不同步的、初始容量 16 和 load factor 0.75
底层原理
hashing 指将对象转为整数值的过程,更方便索引和搜索,HashMap 是由一组头节点组成的数组,节点结构如下
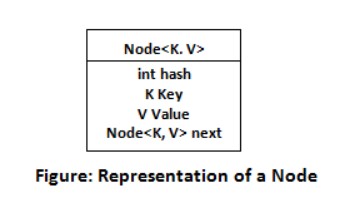
其中每个头节点的下标又称为桶(Bucket),由头节点所构成的一条链表,它的节点都有相同的桶值,这些桶又构成了 HashMap
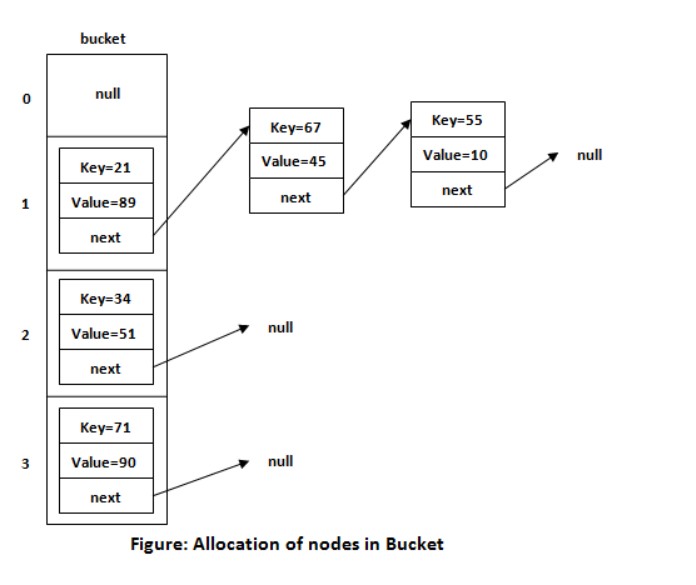
与 HashTable 的区别
| HashMap | HashTable |
| 线程不同步 | 线程同步 |
| 允许有一个空键和多个空值 | 不能有空键和空值 |
| default capacity 16; loadfactor 0.75 | default capacity 11; loadfactor 0.75 |
| 线程不需等待,所以性能高 | 线程需等待,故性能较低 |
| 在 JDK 1.2 引进 | JDK 1.0 就被引进 |
hashMap 中插入键值对的过程
// 1. 添加键值对
HashMap<String, Integer> map = new HashMap<>();
map.put("Tom", 1); // 其 hashcode 为 84274
map.put("Jerry", 2); // hashcode 为 71462654
map.put("Frank", 3); // hashcode 为 68139378
// 2. 计算下标(桶) 公式为 Index= hashcode & (16 - 1)
Index = hashcode & (16 - 1);
// “Tom” -> 2 | "Jerry" -> 14 | "Frank" -> 2
// 3. 当有相同的 hashcode 时,就会调用 equals() 来
// 比较内容是否相同,以此保证无重复
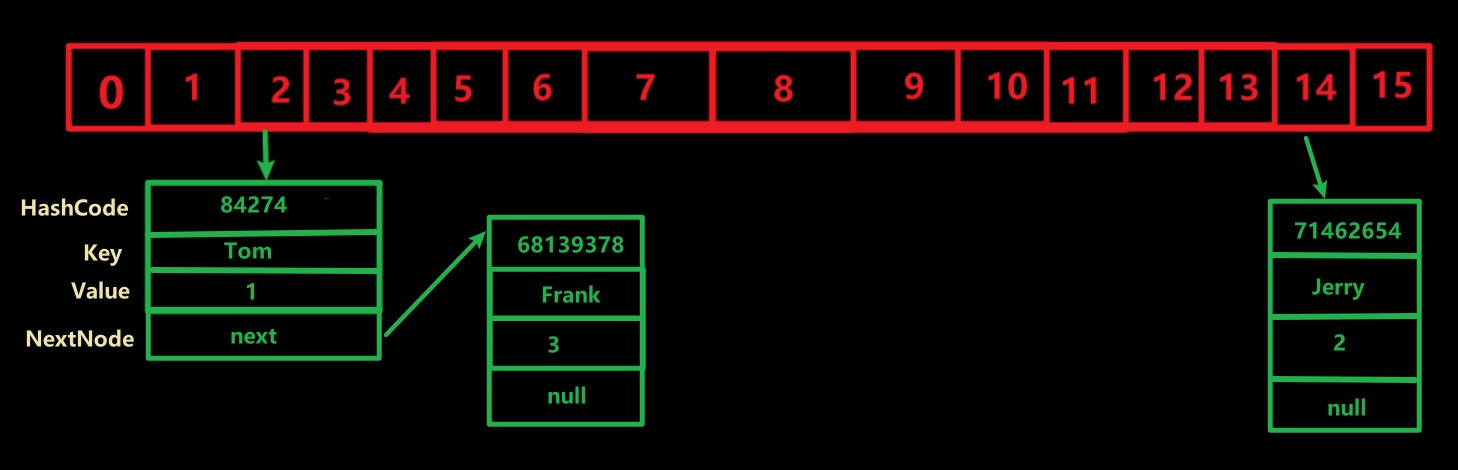
用 map.get(K key) 取值时与之相似,先计算 Hashcode 值,再计算下标,让后通过 equals() 比较所给的 key 与节点的 key 是否相同,相同则将其值返回,不同再与下个节点比较,都不同则返回 null
LinkedHashMap 与 HashMap 相似,只是它在遍历时,则是以插入元素的顺序来输出结果的
TreeMap 则不能有 null 键但能有多个 null 值,且遍历时以键升序的形式遍历,底层是基于红黑树实现的
TreeMap 的一些方法
ceilingEntry(K k) | ceilingKey(K k)// 返回 map 中大于等于所给键值对的最小值,没有则返回 nullfloorEntry(K k) | floorKey(K k)// 返回 map 中小于等于所给键值的最大值,则有返回 nullhigherEntry(K k) | higherKey(K k)// 返回 map 中严格大于所给键的最小值,没有则 nulllowerEntry(K k) | lowerKey(K k)// 返回 map 中严格小于所给键的最大值,没有则 nullfirstEntry() | firstKey()// 返回当前 map 中最小键的映射,若 map 为空则返回 nulllastEntry() | lastKey()// 返回当前 map 中最大键的映射,若 map 为空则返回 nullheadMap(K toKey) | headMap(K toKey, boolean inclusive)// 返回该 map 中严格小于所给键的映射视图,其中 inclusive 为 true 表示包含边界值,即小于等于tailMap(K toKey) | tailMap(K toKey, boolean inclusive)// 与 headMap 相反subMap(K fromKey, boolean fromInclusive, K toKey, boolean toInclusive)// 返回键从 fromKey 到 toKey 的子图subMap(K fromKey, K toKey)// 返回键在 [ fromKey, toKey ) 范围内的子图pollFirstEntry()// 删除并返回该 map 中最小键的映射,若 map 为空则返回 nullpollLastEntry()// 删除并返回该 map 中最大键的映射,若 map 为空则返回 null