JPA
记录 SpringBoot-JPA 的基础操作
学习笔记,仅供参考
参考:青空の霞光视频讲解-JPA 部分 | 官方文档 | 青空の霞光文档-JPA 部分
目录:
- 1. 使用前的配置
- 2. 操作数据
- 3. 自定义 Repository 方法
- 4. 关联查询
- 5. 自定义 SQL 语句
JPA 指 Java Persistent API,即类似于 Mybatis 的一种持久化框架,与 mybatis 不同的是它通过操作实体类自动在数据库中建表,通过接口实现类对象的方法自动生成 SQL 语句操作数据并获取结果。
1. 使用前的配置
本文使用 SpringBoot 框架做练习,所以要先导入 JPA 的依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>随后可以像往常一样新建一个 Java 类
@Data
public class JPAUser {
int id;
String username;
String password;
}
// 通过注解将 Java 类变为数据库对应的实体类
@Data
@Entity // 表明该类为实体类
@Table(name = "user_jpa") // 自动创建的表名
public class JPAUser {
@GeneratedValue(strtegy = GenerationType.IDENTITY) // 生成策略,这里为自增
@Id // 表示该属性为主键
@Column(name = "id") // 对应数据库中表的字段
int id;
@Column(name = "username")
String username;
@Column(name = "password")
String password;
}
// IDEA 中,会在代码的左边栏出现注解成功后一些图标,以作提示
最后还要在 application.yml 中配置一下 jpa
spring:
jpa:
show-sql: true # 开启执行自动生成 SQL 的日志
hibernate:
ddl-auto: create # 自动建表时的策略上述文件中 ddl-auto 属性用于设置自动表的策略,它有4种
create 启动时删数据库中的表,然后创建,退出时不删除数据表(常用于首次建表)
create-drop 启动时删数据库中的表,然后创建,退出时删除数据表 如果表不存在报错
update 如果启动时表格式不一致则更新表,原有数据保留(建完表后的常用策略)
validate 项目启动表结构进行校验 如果不一致则报错
配置完成后,即可启动项目创建表,可在控制台中看到建表的日志,如下所示。同时也能在 mysql 的指定库中看到建成的表
Hibernate: drop table if exists user_jpa
Hibernate: create table user_jpa (id integer not null auto_increment, password varchar(255), username varchar(255), primary key (id)) engine=InnoDB
// 另外若实体类上没有 @Table 注解,它会以类名作为表名注意,在创完表后应把 ddl-auto 的策略改为 update,不然再次启功项目后又重新建表并清空数据
2. 操作数据
在建完表之后,就可向表中增删改查数据了。首先要新建个 repository 接口并继承 JpaRepository 接口,然后通过注入 repository 接口就能使用实现类的方法来 CRUD
@Repository // 类似于 @Mapper,将持久化接口的实现类注册为 Bean 并交给 spring 管理
public interface UserRepository extends JpaRepository<JPAUser, Integer> {
// 上面父接口有两个泛型,分别对应操作表的实体类、表主键的类型
}接着在测试类中使用 repository 对象操作数据
@SpringBootTest
class JpaTestApplicationTests {
@Resource
UserRepository repository;
@Test
void addData() {
// Insert data
JPAUser user = new JPAUser();
user.setUsername("Tom");
user.setPassword("123456");
user = repository.save(user); // 将实体类保存到 DB 中,并返回插入后的结果
System.out.println("Id of inserted data: " + user.getId());
}
@Test
void queryData() {
// query data
repository.findById(1).ifPresent(System.out::println);
// 显示查询结果,这里返回的结果是 Optional 类型,是 Java 8 的新特性
}
@Test
void updateData() {
// update data
JPAUser user = new JPAUser();
user.setId(1);
user.setUsername("Jerry");
user.setPassword("654321");
user = repository.save(user);
System.out.println("updated data: " + user);
// 更新数据与插入都是用的 save 方法
// 方法的逻辑是先查询所给的数据是否存在,存在则更新数据,不在则新增数据
}
@Test
void deleteData() {
// delete data
repository.deleteById(1);
// 也是先查询判断数据是否存在,接着再看是否删除
}
}从上面就能够看出,操作数据都是 JpaRepository 接口 API 所提供的,而它的方法又是继承自 CrudRepository 接口,所以下面就具体了解它的方法。jpa-doc 官方 api 文档
long count()// 返回当前表中有多少条数据delete(T entity)// 从表中删除给定的数据,存在则删除,其中所给实体必须含有主键 iddeleteAll()// 删除表中所有的数据deleteAll(Iterable<? extends T> entities)// 从表中删除所给集合含有的数据,且集合不能为 null 和空集合deleteById(ID id)// 根据 id 从表中删除数据deleteAllById(Iterable<? extends ID> ids)// 根据 id 集合从表中删除数据boolean existsById(ID id)// 判断表中是否存在指定 id 的数据Iterable<T> findAll()// 获取表中所有的数据Iterable<T> findAllById(Iterable<ID> ids)// 依据所给的 id 集合从表中获取对应的数据Optional<T> findById(ID id)// 获取指定 id 数据<S extends T> S save(S entity)// 在表中保存所给数据,并且返回保存后的结果<S extends T> Iterable<S> saveAll(Iterable<S> entities)// 在表中保存所给的数据集合,并将结果返回
另外 PagingAndSortingRepository
Page<T> findAll(Pageable pageable)// 以分页的形式查询数据Iterable<T> findAll(Sort sort)// 以排序的形式查询数据// ****分页方法的使用***** repository.findAll(PageRequest.of(0, 2)).forEach(System.out::println); // 由继承关系可知,Page 继承 Iterator 接口,即也属于集合类,故返回结果可用 forEach 输出 // 而 PageRequest 为 Pageable 的实现类,of(0, 1) 方法参数中 0 指获取第一页的结果,2 指表中数据 2 个作一页 // 执行的 sql 是,先由 size 参数做 limit 查询将表中数据按 size 分页,随后再由 page 查出对应页的结果,page 是从 0 开始 // ****排序方法的使用***** repository.findAll(Sort.by(Sort.Direction.DESC, "username")).forEach(System.out::println); // 通过 Sort.by(Drection d, String... property) 获取 Sort 对象,将其交给 findAll() // Drection 指明升降序、property 指对那个字段排序,且两者都不能为 null // 执行的 sql 为 "..order by property desc" repository.findAll(Sort.by(Sort.Order.asc("username"))) .forEach(System.out::println); // 另一种方法重载 // 值得注意的是,在 springboot2.2.1(含)以上的版本Sort已经不能再实例化了,构造方法已经是私有的了
3. 自定义 Repository 方法
前面使用的都是 JpaRepository 提供的方法来操作数据库,但这些远远不够应付各种操作数据的需求,所以 JPA 框架还支持自定义方法来满足要求。添加方法也很简单,只需在 UserRepository,即自己写的 Repository 接口中规定好行为即可使用。
@Repository
public interface UserRepository extends JpaRepository<JPAUser, Integer> {
// 根据用户名查询数据
JPAUser findByUsername(String username);
// 根据用户名和 id 查询
JPAUser findByUsernameAndId(String username, int id);
// 对用户名做模糊查询
List<JPAUser> findByUsernameLike(String username)
// 判断表中是否存在所给 ID 的数据
boolean existsById(int id);
}
// =======自定义方法的使用=======
@SpringBootTest
class JpaTestApplicationTests {
@Resource
UserRepository repository;
@Test
void contextLoads() {
repository.findByUsername("Tom");
repository.findByUsernameAndId("Tom", 1);
repository.findByUsernameLike("%T%").forEach(System.out::println);
repository.existsById(1);
}
}下面列举出可支持的各种条件查询组合,且在 IDEA 中会智能地给出提示
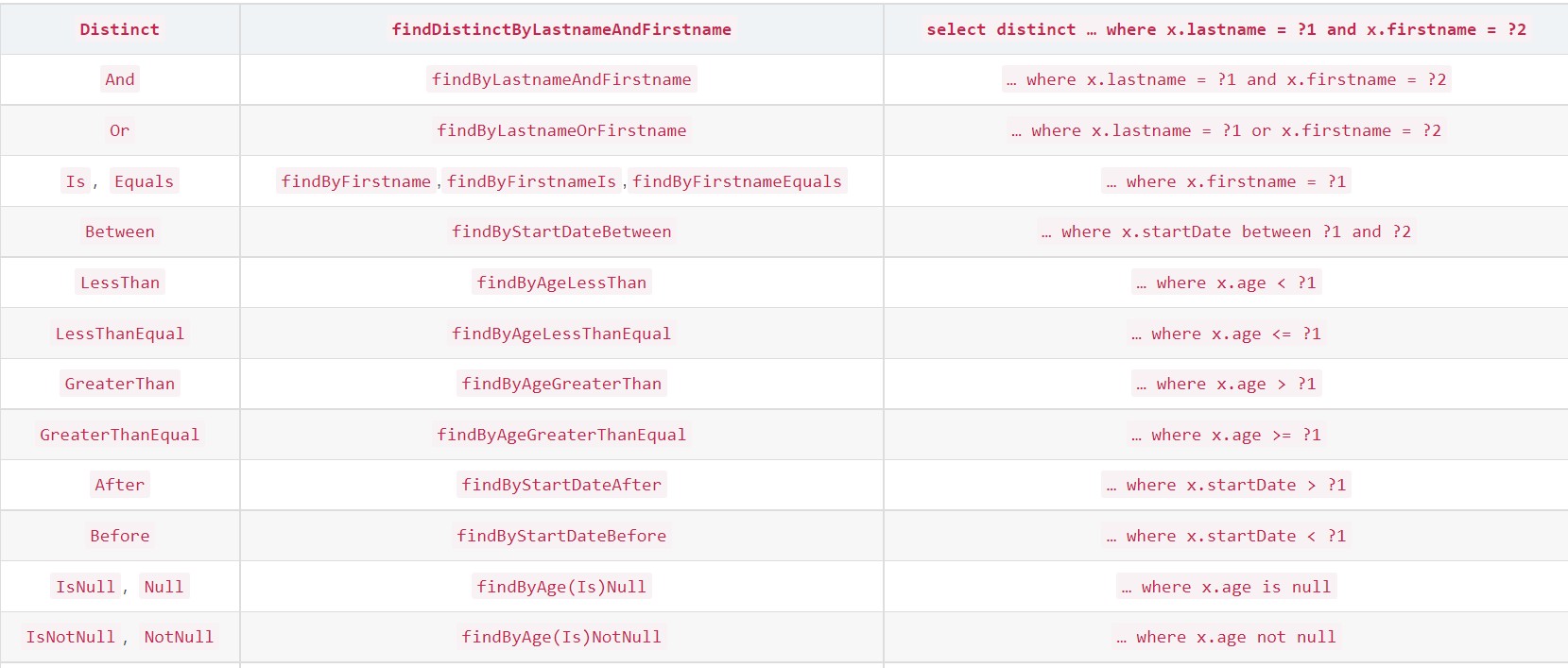
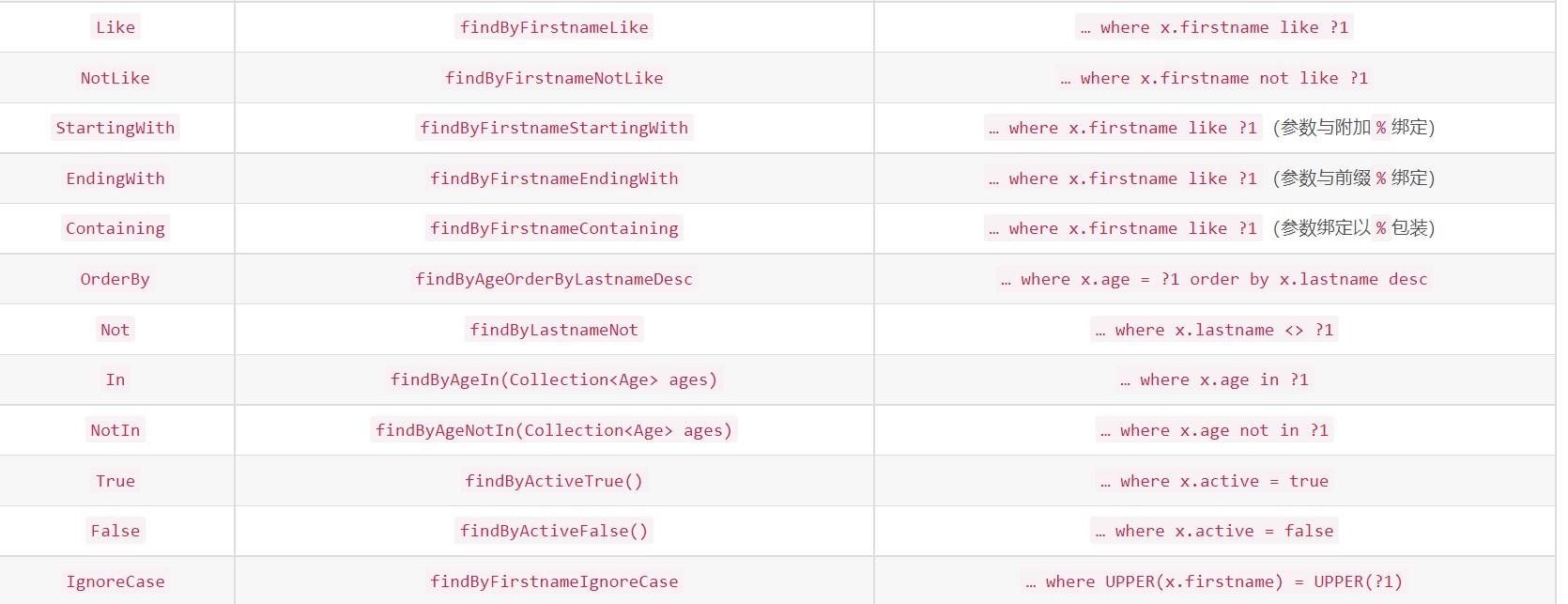
4. 关联查询
在学习 mysql 时,表与表之间可以通过外键建立关联,或者在查询时可以做关联查询,下面看看 JPA 中是如何实现这些功能的。
4.1. 一对一
下面以用户表及用户详细表为例,展现一对一的关系
// ======用户详细表的实体类=====
@Data
@Entity
@Table(name = "user_jpa_detail")
public class JPAUserDetail {
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
@Id
int id;
@Column(name = "address")
String address;
@Column(name = "phone")
String phone;
@Column(name = "email")
String email;
}
// ======用户表的实体类=====
@Data
@Entity
@Table(name = "user_jpa")
public class JPAUserDetail {
// ... (原有字段)
@JoinColumn(name = "detail_id") // 指定关联字段名称
@OneToOne // 声明为一对一关系
JPAUserDetail detail; // 将关联表对象作为一个属性
}
// ======启动项目后的相关日志信息=====
Hibernate: alter table user_jpa add column detail_id integer
Hibernate: create table user_jpa_detail (id integer not null auto_increment, address varchar(255), email varchar(255), phone varchar(255), primary key (id)) engine=InnoDB
Hibernate: alter table user_jpa add constraint FK6nuktj5eyuqbyyrag4cdgvrnc foreign key (detail_id) references user_jpa_detail (id)
// 1. 先在 user_jpa 中加入外键字段;2. 创建关联表;3. 将外键字段与关联表对应字段绑定
// ======完善两表的信息后的查询结果=====
repository.findById(3).isPresent(System.out::println);
// result:
JPAUser(id=3, username=Frank, password=74751, detail=JPAUserDetail(id=2, address=ShangHai, phone=24680, email=123@bb,com))从上面的结果中可以看出,在对用户表查询时,对应的详情表信息也会自动地显示出来。当然通过配置可以关闭这种关联表的自动显示,从而让查询更加灵活可变。
// ======修改用户表的实体类=====
@Data
@Entity
@Table(name = "user_jpa")
public class JPAUserDetail {
// ... (原有字段)
@JoinColumn(name = "detail_id")
@OneToOne(fetch = "FetchType.LAZY") // 将一对一关系的获取方式改为懒加载模式
JPAUserDetail detail;
}
// ======测试懒加载=====
@Transactional // 懒加载属性需要在事务环境下获取,因为repository 方法调用完后 Session 会立即关闭
@Test
void test() {
repository.findById(1).ifPresent(account -> {
System.out.println(account.getUsername()); //获取用户名
System.out.println(account.getDetail()); //获取详细信息(懒加载)
});
}
// 这样是否显示详情表结果就可控制
// ====一些验证====
★ 上面的 test 方法在 Eager(积极加载) 下也是可以控制是否显示详情表信息,所以得出详情表结果是否输出与懒加载无关
而查询效率是与懒加载有关的,下面是两种加载方式的一些对比
1)懒加载
【不使用关联对象】
Hibernate: select jpauser0_.id as id1_0_0_, jpauser0_.detail_id as detail_i4_0_0_, jpauser0_.password as password2_0_0_, jpauser0_.username as username3_0_0_ from user_jpa jpauser0_ where jpauser0_.id=?
【使用关联对象】
Hibernate: select jpauser0_.id as id1_0_0_, jpauser0_.detail_id as detail_i4_0_0_, jpauser0_.password as password2_0_0_, jpauser0_.username as username3_0_0_ from user_jpa jpauser0_ where jpauser0_.id=?
Frank
Hibernate: select jpauserdet0_.id as id1_1_0_, jpauserdet0_.address as address2_1_0_, jpauserdet0_.email as email3_1_0_, jpauserdet0_.phone as phone4_1_0_ from user_jpa_detail jpauserdet0_ where jpauserdet0_.id=?
JPAUserDetail(id=2, address=ShangHai, phone=24680, email=123@bb,com)
2)积极
【不使用关联对象】
Hibernate: select jpauser0_.id as id1_0_0_, jpauser0_.detail_id as detail_i4_0_0_, jpauser0_.password as password2_0_0_, jpauser0_.username as username3_0_0_, jpauserdet1_.id as id1_1_1_, jpauserdet1_.address as address2_1_1_, jpauserdet1_.email as email3_1_1_, jpauserdet1_.phone as phone4_1_1_ from user_jpa jpauser0_ left outer join user_jpa_detail jpauserdet1_ on jpauser0_.detail_id=jpauserdet1_.id where jpauser0_.id=?
【使用关联对象】
Hibernate: select jpauser0_.id as id1_0_0_, jpauser0_.detail_id as detail_i4_0_0_, jpauser0_.password as password2_0_0_, jpauser0_.username as username3_0_0_, jpauserdet1_.id as id1_1_1_, jpauserdet1_.address as address2_1_1_, jpauserdet1_.email as email3_1_1_, jpauserdet1_.phone as phone4_1_1_ from user_jpa jpauser0_ left outer join user_jpa_detail jpauserdet1_ on jpauser0_.detail_id=jpauserdet1_.id where jpauser0_.id=?
Frank
JPAUserDetail(id=2, address=ShangHai, phone=24680, email=123@bb,com)
从对比结果可看出,积极加载下无论是否使用关联对象都是一样的 SQL 语句,即对两表联合查询
而懒加载下的不使用关联对象仅对主表查询,若要用关联对象就再对从表查询既然可以关联查询,那么也能关联性地一次完成两张表的数据插入
// 还是先对外键字段修改配置
@JoinColumn(name = "detail_id")
@OneToOne(fetch = "FetchType.LAZY", cascade = CascadeType.ALL) // 设置级联类型为 All
JPAUserDetail detail;
// 四种级联类型:All 所有操作均关联 | Persist 插入时才关联 | Remove 删除才关联 | Merge 修改才关联
// ====具体使用====
@Test
void test() {
JPAUserDetail detail = new JPAUserDetail();
detail.setAddress("Beijing");
detail.setEmail("123@qq.com");
detail.setPhone("55193");
JPAUser user = new JPAUser();
user.setUsername("Tom");
user.setPassword("202285");
user.setDetail(detail);
user = repository.save(user);
System.out.println("主键ID: " + user.getId() + " | 外键ID: " + user.getDetail().getId());
// 级联操作时,先对从表操作,再对主表操作
}4.2. 一对多
下面以用户成绩表为例,来展现一对多的关系。注意:在一对多的关联中,多端应该含有一个存放一端的主键
// =====用户成绩表======
@Data
@Entity
@Table(name = "user_jpa_score")
public class JPAUserScore {
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
@Id
int id; // 成绩表的主键
@Column(name = "score")
double score; // 成绩字段
@OneToOne
@JoinColumn(name = "subject_sid")
JPAUserSubject subject; // 关联学科表的外键
@Column(name = "uid")
int uid; // 存放主表的主键
}
// =====用户学科表======
@Data
@Entity
@Table(name = "user_jpa_subject")
public class JPAUserSubject {
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "sid")
@Id
int sid; // 学科表主键,与成绩表一对一关联
@Column(name = "name")
String name; // 学科名称
@Column(name = "teacher")
String teacher; // 任教老师
@Column(name = "time")
int time; // 学科学时
}
// =====用户表添加成绩字段======
@JoinColumn(name = "uid") // 关联成绩表中的 uid 字段
@OneToMany(fetch = FetchType.LAZY, cascade = CascadeType.REMOVE) // 采用懒加载,且删除时进行关联操作
List<JPAUserScore> score; // 一对多关系的字段必须是集合容器
// ====使用====
@Transactional
@Test
void test() {
repository.findById(3).ifPresent(jpaUser -> {
System.out.println("name: " + jpaUser.getUsername());
jpaUser.getScore().forEach(jpaUserScore -> {
System.out.println("subject: " + jpaUserScore.getSubject().getName() + " | teacher: " + jpaUserScore.getSubject().getTeacher());
System.out.println("score: " + jpaUserScore.getScore());
});
});
}
// ====控制对应日志====
Hibernate: select jpauser0_.id as id1_0_0_, jpauser0_.password as password2_0_0_, jpauser0_.username as username3_0_0_ from user_jpa jpauser0_ where jpauser0_.id=?
name: Frank
Hibernate: select score0_.uid as uid3_2_0_, score0_.id as id1_2_0_, score0_.id as id1_2_1_, score0_.score as score2_2_1_, score0_.subject_sid as subject_4_2_1_, score0_.uid as uid3_2_1_, jpausersub1_.sid as sid1_3_2_, jpausersub1_.name as name2_3_2_, jpausersub1_.teacher as teacher3_3_2_, jpausersub1_.time as time4_3_2_ from user_jpa_score score0_ left outer join user_jpa_subject jpausersub1_ on score0_.subject_sid=jpausersub1_.sid where score0_.uid=?
subject: Chinese | teacher: 张三
score: 89.0
subject: Math | teacher: 李四
score: 92.0
subject: English | teacher: 王五
score: 77.04.3. 多对一
在一对多的基础上,将学科表的教师字段关联一张教师表,以此展示多对一关系。
// ====教师表====
@Data
@Entity
@Table(name = "user_jpa_teacher")
public class JPAUserTeacher {
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "tid")
@Id
int id; // 主键 Id
@Column(name = "name")
String name; // 教师名
@Column(name = "sex")
String sex; // 性别
}
// ====学科表的教师字段修改====
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "tid") // 与一对一的一样,作为外键且不用在从表中加主表主键属性
JPAUserTeacher teacher;
// ====使用====
@Test
@Transactional
void test() {
repository.findById(3).ifPresent(jpaUser -> {
System.out.println("Username: " + jpaUser.getUsername());
jpaUser.getScore().forEach(jpaUserScore -> {
System.out.println("Subject: " + jpaUserScore.getSubject().getName());
System.out.println("Teacher: " + jpaUserScore.getSubject().getTeacher().getName() +
" | Sex: " + jpaUserScore.getSubject().getTeacher().getSex());
System.out.println("Score: " + jpaUserScore.getScore());
});
});
}4.4. 多对多
多对多关系虽然复杂,但操作上只需引出一张关系表即可。JPA 会自动创建一张中间表,并自动设置外键,就可以将多对多关联信息编写在其中了
// ====学科表中教师字段的修改====
@ManyToMany(fetch = FetchType.LAZY) //多对多场景
@JoinTable(name = "teach_relation", //多对多中间关联表
joinColumns = @JoinColumn(name = "cid"), //当前实体主键在关联表中的字段名称
inverseJoinColumns = @JoinColumn(name = "tid") //教师实体主键在关联表中的字段名称
)
List<JPAUserTeacher> teacher;小总结:关联指两张表数据相关联,一对一指主从表数据一一关联;一对多指主表数据关联从表的多个数据;多对一指主表多个数据关联从表一个数据;多对多可理解为前三种关系的各种组合
5. 自定义 SQL 语句
虽然 JPA 能够自动化地生成 sql 语句,但有时候并不一定就效率高,所以需要手动编写 sql。JPA 能够编写 JPQL 语言和原生的 SQL 语言,只不过 JPQL 是面向对象的。
下面以更新给定用户 ID 的数据为例,说明两种语言的差异
// ====JPQL 语言=====
@Repository
public interface UserRepository extends JpaRepository<JPAUser, Integer> {
@Transactional // DML 操作需要事务环境,可以不在这里声明,但是调用时一定要处于事务环境下
@Modifying // 表示这是一个DML操作
@Query("update JPAUser set password = ?2 where id = ?1") // 这里操作的是一个实体类对应的表,参数使用?代表,后面接第n个参数
int updatePasswordById(int id, String newPassword);
}
@Test
void test(){ // 使用
repository.updatePasswordById(1, "654321");
}
// ====原生 SQL====
@Repository
public interface UserRepository extends JpaRepository<JPAUser, Integer> {
@Transactional // DML 操作需要事务环境,可以不在这里声明,但是调用时一定要处于事务环境下
@Modifying // 表示这是一个DML操作
@Query(value = "update user_jpa set password = :pwd where username = :name", nativeQuery = true) // 使用原生SQL,和Mybatis一样,这里使用 :名称 表示参数,当然也可以继续用上面那种方式。
int updatePasswordByUsername(@Param("name") String username, //我们可以使用@Param指定名称
@Param("pwd") String newPassword);
}