ARM Assembly
ARM 汇编基础知识
学习笔记,仅供参考
在学习 FreeRTOS 中要使用 ARM 汇编语言来编写系统的调度、切换等操作,之前这块知识空白所以补下基础,目的只为能看懂 ARM 汇编程序
一些概念
参考视频主要以实操为主,所以一些概念参考这篇博客 writing-arm-assembly
arm与x86区别:主要是指令集不同,x86 CISC - 有丰富的指令来访问内存,因此有更多的操作、取值模式,但寄存器较少; ARM RISC - 指令较少、寄存器较多,只使用 Load/Stroe 指令访问内存,即对一块内存做加法就要三步(1. 将数据从内存取到 CPU,2. CPU 做加法操作, 3. 再将运算结果存入内存)。RSIC的优点之一:由于每条指令都较为精简,所以执行快效率高。另外,arm 还分为两种模式 ARM 和 Thumb
更多区别:
- ARM 大多指令能用作条件执行
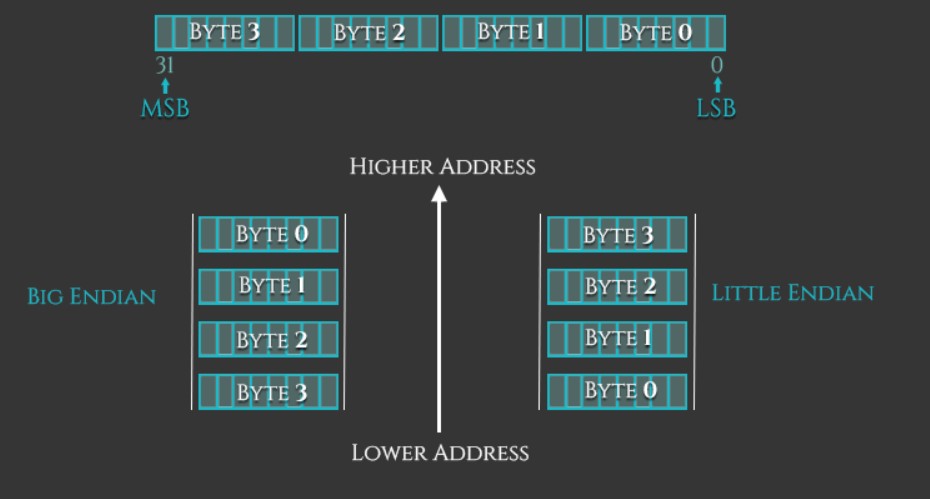
- Intel x86 使用小端存储(数据地位放在低地址)
- ARM v3 前使用小端存储、之后变为大小端可切换的存储模式
除了 ARM 与 x86 之间有区别外,ARM 的不同版本也会区别

由于计算机只认识机器码,所以汇编程序还要先转为机器码才行,因此汇编器充当了这一角色。同时汇编语言的出现也减轻了程序员编写代码的压力,通过近似自然语言的文本字符来告诉计算机完成怎样的操作。
数据结构:汇编中数据通常是以字、半字、字节的形式存取数据,在指令后添加对应的后缀来表示不同的数据形式,-h 表示半字、-b 表示字节、无后缀默认为字。
/* 不同数据类型的 Load (Store 类型) */
ldr // load word
ldrh // load unsigned half word
ldrsh // load signed half word
ldrb // load unsigned byte
ldrsb // load signed byte
大小端:上面说过,ARM 支持大小端存储数据,大小端的判断就是根据数据高低位谁放在低地址。而切换大小端模式的位是 CPSR 的第九位(E bit)决定
寄存器:常见到的 16 个寄存器 r0~r15,可分为 2 组,通用寄存器和特殊寄存器。
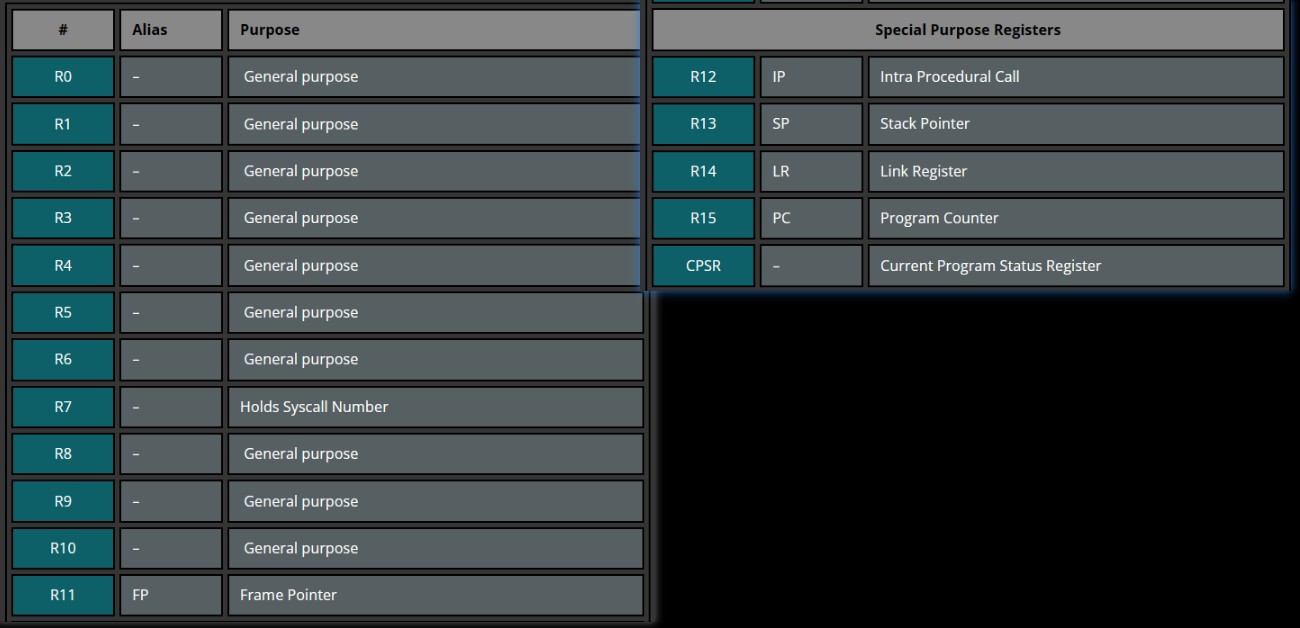
R0-R12 用于存放数值或内存地址。例如R0能作为算数运算结果或函数返回值;R7能用于 systemcall;R11能用于跟踪栈指针;而且函数调用的前四个参数存放在 r0-r3
R13(SP-Stack Pointer)栈顶指针,用于压栈出栈操作
R14(LR-Link Register)当有子程序或异常时LR会保存当前指令的下条指令的地址,可让程序从子程序跳回主程序
R15(PC-Program Counter)每执行一条指令就自增一次,ARM通常是4字节,Thumb是2字节。当执行分支指令时,PC 的值会加8字节
CPSR (Current Program Status Register)用于表示当前程序的一些状态

下面是对一些标志位的描述
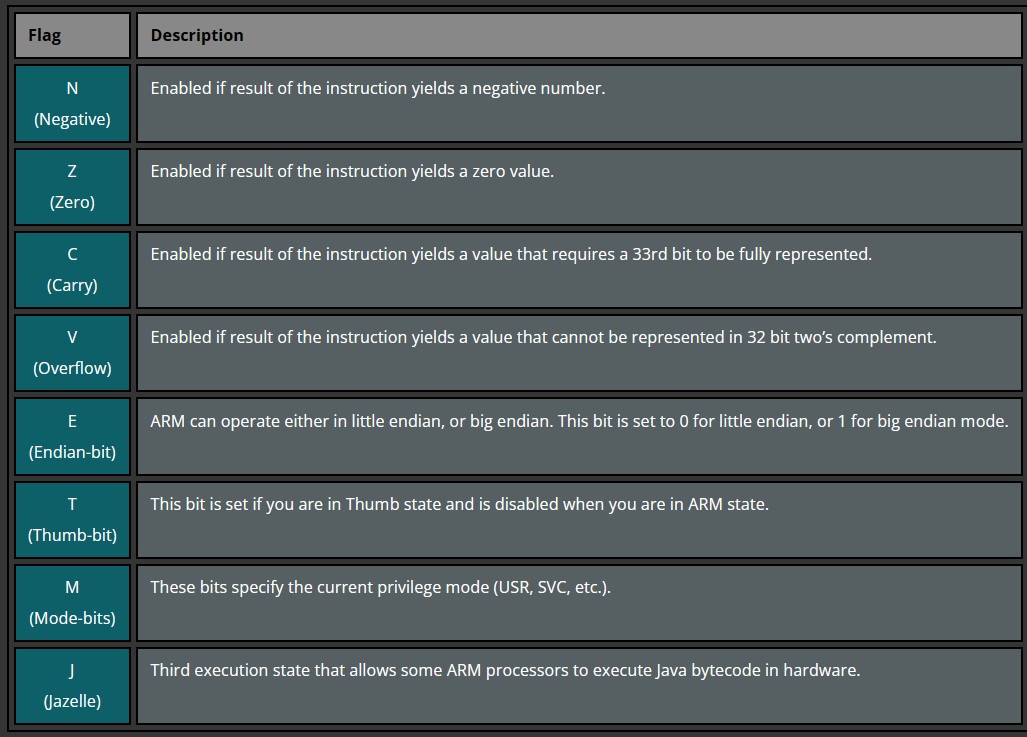
ARM 常见指令集
存取指令(Load/Store)
/* 将 list 的地址存入 r0,即 r0 = &list[0] */
ldr r0, =list
/* 将 r0 值对应的地址的数据存入 r1,即 r1 = list[0] */
ldr r1, [r0]
/* 将 r0 值加 4 对应地址的数据存入 r2,即 r2 = list[1]
另外,加数必须为 4 的倍数,一个地址占 4 字节 */
ldr r2, [r0, #4]
/* 将 r0 值对应地址的数据存入 r3,然后 r0 再加 4,
即 r3 = list[0], r0 += 4 */
ldr r3, [r0], #4
/* 多数据加载,将 r2 对应地址的值加载到 r0,然后再将地址+1的值
加载到 r4,依次类推加载到 r6 为止 */
ldm r2, {r0, r4-r6}
/* !表示将最后的地址写回到 r2 */
ldm r2!, {r0, r4-r6}
/* Store 存数据也是类似情形 */算术运算(+、-、*)
/* 加减乘 */
add r2, r1, r0 // r2 = r1 + r0
sub r2, r1, r0 // r2 = r1 - r0
mul r2, r1, r0 // r2 = r1 * r0
/* 注意:普通的算数运算指令不会设置 CPSR 的标志位,所以当一些算数产生进位、借位
溢出时我们就无法得知,所以就有了下面这些拓展指令 */
adds r2, r1, r0
subs r2, r1, r0
muls r2, r1, r0
/* 带进位借位运算 */
ADC r2, r1, r0 // r2 = r1 + r0 + carry_bit
SBC r2, r1, r0 // r2 = r1 - r0 - carry_bit
位运算(与或非)
/* 与、或、异或 */
and r1, r0, #0xf // r1 = r0 & (0xf)
orr r1, r0, #0xf // r1 = r0 | (0xf)
eor r1, r0, #0xf // r1 = r0 ^ (0xf)
/* 赋值与取反 */
mov r0, #0xf // r0 = 0xf
mvn r0, #0xf // r0 = ~(0xf)
移位和循环移位
/* 左移 */
lsl r0, #1 // 对 r0 的值左移 1 位,立即数范围:0-31
lsl r1, r0 // 对 r1 的值左移 r0 值个位
lsl r1, r0, #1 // 将 r0 值左移移位存入 r1 中
/* 右移 */
lsr r0, #1 // r0 值右移 1 位,立即数范围:1-32
/* 循环右移 */
ror r0,#1 // r0 值向右循环移 1 位
ror r1, r0, #1
/* 注意:参与移位的寄存器必须为 r0-r7 */条件与执行
/* 比较 - 即计算 r1 - r0 的差值,若为 +,CSPR N 位置 0,
为 -,CPSR N 位置 1,为 0,CPSR Z 位置 1 */
cmp r1, r0
/* 通过 cmp 指令设置 CPSR 标志位,即可判断大小 */
BGT label // 若 N=0,Z=0, 跳至 label 执行
BLT label // 若 N=1,Z=0, 跳至 label 执行
BEQ label // 若 N=0,Z=1, 跳至 label 执行
BGE(≥), BLE(≤), BNE(!=)
B label // 跳转到 label
/* 条件跳转示例--遍历数组 */
.data
list: // 定义数组,并获取数组长度
.word 1, 2, 3, 4, 5, 6, 7, 8, 9, 10
.equ listend,(.-list)/4
.global _start
_start: // 初始化寄存器
ldr r0, =list // r0 作数组下标
mov r2, #0
mov r3, #0
sum: // 遍历数组求和
ldr r3, [r0], #4 // 取出数组当前下标值,下标向后移
add r2, r3 // r2 += r3
cmp r3, #listend // 判断下标是否超出数组长度
blt sum // 未超出跳至 sum 循环遍历
.end
/* 除了跳转可与条件结合使用外,算数运算也行,并组合成新指令 */
movlt r0, #1 // 若条件满足,r0=1
addgt r1, #2 // 若条件满足,r1+=2
栈与函数
/* 函数调用与返回 */
bl label // 跳转 label 处执行,同时 LR 存入 bl 指令下条指令地址
bx lr // 常用于子函数结尾,表示跳至 LR 所存地址处执行,即回到主函数
/* 栈--保护/恢复现场 */
push {r0, r1} // 将当前寄存器的值压栈
mov r0, #0 // 执行一些语句,可能会改变寄存器值
pop {r0, r1} // 出栈恢复寄存器值
/* 栈的一些用法:
1. 在调用函数前,将 reg 值压栈,防止子函数覆盖掉 reg 值,返回后再出栈
2. 在子函数中压栈,在主函数中出栈,可获取子函数的返回值*/由于视频这里只是简单描述,还是参考azeria进一步了解
栈是块内存区域,当进程创建时会在栈中分配一块内存空间。常存放函数的全局变量、局部变量、返回值等。另外上面的 PUSH、POP 只是栈操作的别名,而非正真的指令
栈的实现方式两个维度:1. 栈顶指针可向下(descending)还是向上(ascending)增长,2. 通过判断 SP 当前指向栈内数据(full)还是栈外空数据(empty)
由此可组合成四种实现方式:满递增、满递减、空递增、空递减
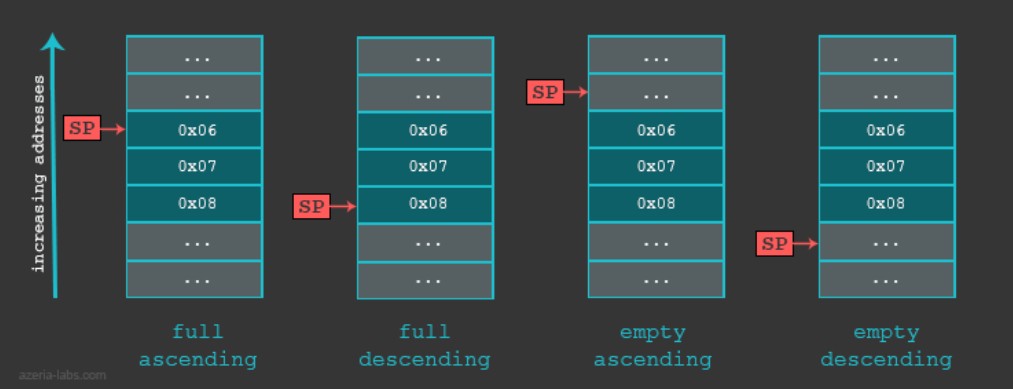
由栈的实现再结合 Load/Store 完成多数据存取,见下表
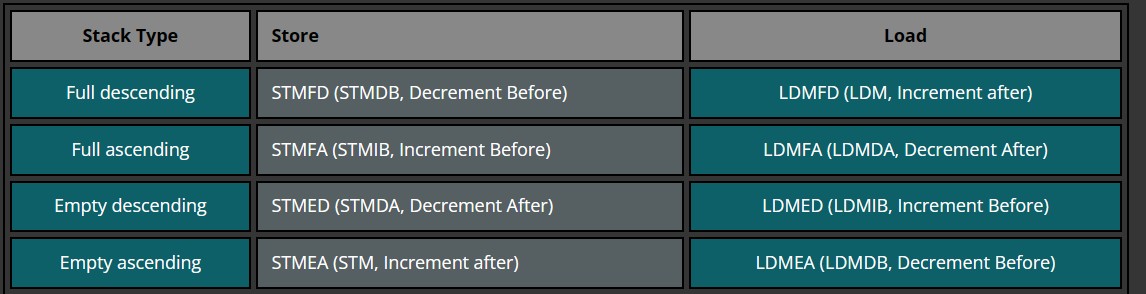
其中,FD(full descending)、FA、ED、EA(empty ascending) 后缀用于堆栈操作(以SP作基地址),IA(increment after)、IB、DA、DB(decrement before) 后缀用于数据操作(以寄存器值作基地址)
栈帧:栈中一块含有特殊功能的内存,在函数调用时创建,栈帧指针(Frame Pointer)通常指向栈帧底部,然后分配栈缓冲区来作为栈帧。栈帧包含返回地址(LR)、前一个栈帧指针、一些需要保护的寄存器、函数参数(超过4个)、局部变量等。在函数结束时被销毁
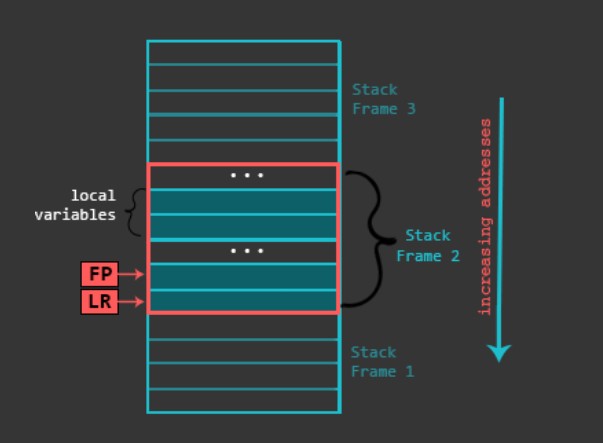
下面是 C 语言调用函数对应的汇编:
/* C - 找出两数的最大值 */
int main(void)
{
int a = 1, b = 2, res = 0;
res = max(a, b);
return 0;
}
int max(int a, int b)
{
return (a > b) ? a : b;
}
/* arm asm */
main:
stmfd sp!, {fp, lr}
add fp, sp, #4 // 创建 fp
sub sp, sp, #16 // 分配栈帧内存
mov r3, #1 // 向栈帧中存数据
str r3, [fp, #-8]
mov r3, #2
str r3, [fp, #-12]
mov r3, #0
str r3, [fp, #-16]
ldr r0, [fp, #-8] // 取数据
ldr r1, [fp, #-12]
bl max
str r0, [fp, #-16]
mov r3, #0
mov r0, r3
sub sp, fp, #4 // 释放栈帧
ldmfd sp!, {fp, pc}
max:
str fp, [sp, #-4]!
add fp, sp, #0
sub sp, sp, #12
str r0, [fp, #-8]
str r1, [fp, #-12]
ldr r2, [fp, #-12]
ldr r3, [fp, #-8]
cmp r2, r3
movge r3, r2
movlt r3, r3
mov r0, r3
add sp, fp, #0
ldmfd sp!, {fp}
bx lr
函数:从上面汇编中,可将函数分为三部分:Prologue(前言), Body(主体), Epilogue(后记)。以 max 函数为例
/* Prologue - 保护前一程序的状态,并创建栈帧 */
str fp, [sp, #-4]!
add fp, sp, #0
sub sp, sp, #12
/* Body - 完成函数功能,初始化参数、比较数值大小 */
str r0, [fp, #-8]
str r1, [fp, #-12]
ldr r2, [fp, #-12]
ldr r3, [fp, #-8]
cmp r2, r3
movge r3, r2
movlt r3, r3
mov r0, r3
/* Epilogue - 销毁栈帧,恢复现场,返回到主函数 */
add sp, fp, #0
ldmfd sp!, {fp}
bx lr值得注意的是,在 Body 中是使用寄存器 r0-r3 来存放函数参数的,若函数参数大于 4 个时,就会将参数存放到栈内存中。另外,mov r0, r3 指将最后函数的返回值放入 r0 中,由于寄存器是 32 bit,若返回值为 64 bit 那么就会用 r1 存放另一半数据。
此外,可根据函数 Body 是否调用其他函数来将函数分为 leaf function(叶子没有分支调用,如 max) 和 no-leaf function(非叶子有分支,如 main)
同时,再来比较下两类函数 Prologue 和 Epilogue 的区别
/* Prologue */
main:
stmfd sp!, {fp, lr}
add fp, sp, #4
sub sp, sp, #16
max:
str fp, [sp, #-4]!
add fp, sp, #0
sub sp, sp, #12
/* no-leaf 在保护现场时还将 lr 寄存器压栈 */
/* Epilogue */
main:
sub sp, fp, #4 // 释放栈帧
ldmfd sp!, {fp, pc}
max:
add sp, fp, #0
ldmfd sp!, {fp}
bx lr
/* leaf 在函数结尾时跳至 lr 以返回到主函数 */基础的指令就先到这里,指令这种东西跟函数一样记是记不住的,只有遇到了在积累,看的多了就明白了
QEMU 模拟 ARM 环境
通过 QEMU 来模拟 Raspberry 的 ARM 环境,以便更真实地编写汇编。本文是以 Ubuntu 18.04 作为安装环境的系统。
首先在 2017-04-10-raspbian-jessie 中下载
2017-04-10-raspbian-jessie.zip压缩包,并使用 unzip 解压得到 img 镜像包然后到 dhruvvyas90/qemu-rpi-kernel clone 或下载此库,里面包含多个 kernel 文件,只使用
kernel-qemu-4.4.34-jessie在 Ubuntu 上安装 QEMU,使用
sudo apt-get install qemu-system命令使用 qemu-system-arm 命令模拟运行 raspberry,具体命令:
qemu-system-arm -kernel ~/..path/kernel-qemu-4.4.34-jessie -cpu arm1176 -m 256 -M versatilepb -serial stdio -append "root=/dev/sda2 rootfstype=ext4 rw" -hda ~/..path/2017-04...jessie.img -net nic -net user,hostfwd=tcp::5022-:22 -no-reboot该命令含义指:内核和镜像选择下载的,CPU 为 arm1176,内存大小 256m,模拟的虚拟机为 versatilepb,外设串口 stdio,设置 root 及文件系统,配置网络端口 5022在开启 raspberry 虚拟机后,打开其终端输入
sudo service ssh start开启 ssh 服务,另外默认用户名为:pi,密码:raspberry在 Ubuntu 中输入
ssh pi@127.0.0.1 -p 5022进入 raspberry 虚拟机,即可在 Ubuntu 上使用虚拟机
Hello World 编写及 DGB 调试
汇编之 Hello World
前面的汇编都是处理数据,那么是如何处理字符串呢?以及如何让它显示到控制台上?下面就一一解释
/* 汇编程序-在控制台打印 Hello world */
.global _start
_start:
mov r0, #1 // 设置 file description 为 1,即 stdout
ldr r1, =message // 取字符串地址到 r1
ldr r2, =len // 取字符串长度到 r2
mov r7, #4 // syscall-write
swi 0 // 软中断
mov r7, #1 // syscall-exit
swi 0
.data
message: // 以 ASCII 码形式存储字符串,message 指向该字符串
.asciz "hello world!\n"
len = .-message // 获取字符串长度
从上面程序中,能看出 r0、r1、r2、r7 都不是随便设置的,而是有某种含义,其中 r7 从前文中了解有 system call 功能,它的值就是 syscall number,所以根据这点可以查看 system call 表格,具体链接在此arm-32_bit_EABI,找到对应 arm 32bit 对应的 system call table,部分如下图
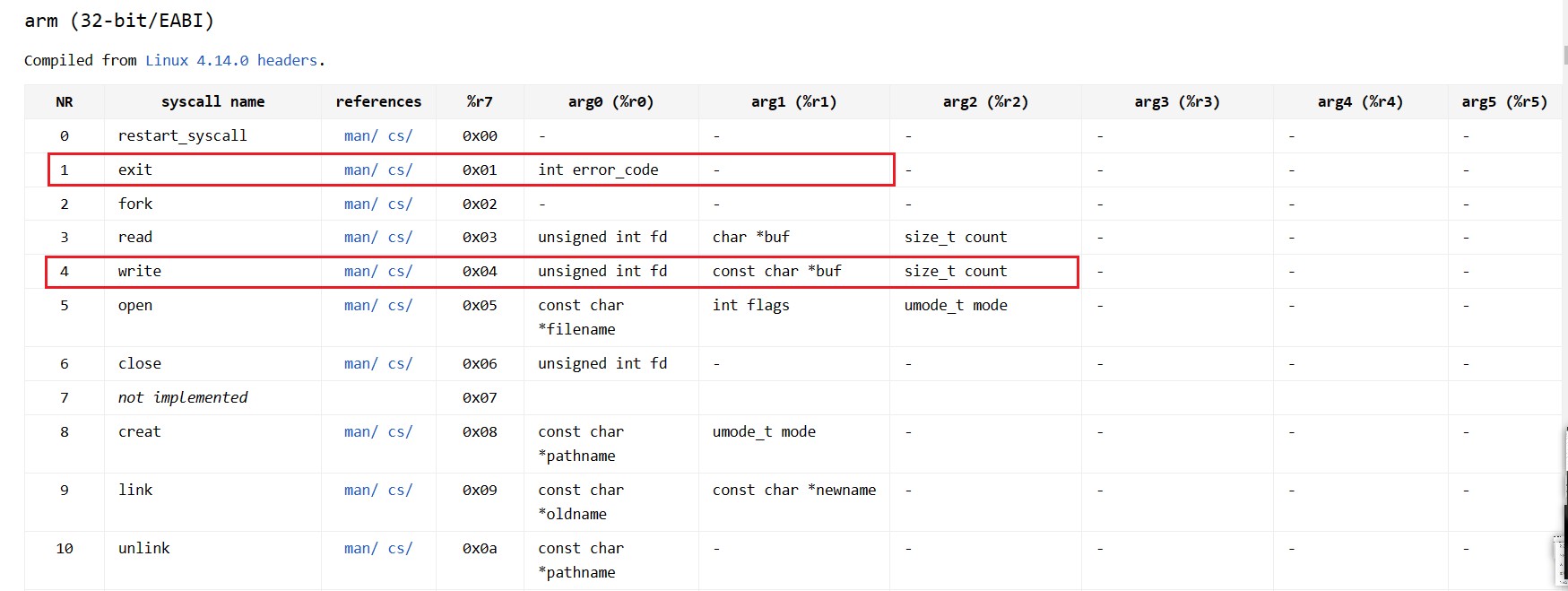
根据表格就能理解 r0、r1、r2、r7 要如此设置了,首先 r7=4 代表调用 syscall-write,调用后 r0 的值就是 write 文件描述符,而在 Linux 中前三个 fd 分别为 stdin(0), stdout(1), stderr(2),所以是向 stdout 写数据;r1 此时就是写字符串的首地址,所以要获取 message 的地址;r2 就是写字符串的长度。swi 0 可能跟系统调用要求有关
在指向完写字符串后,r7=1 表示要调用 syscall-exit 即退出系统调用,可以理解为关闭 stdin 的写字符流,并且此时 r0 的值代表错误码
反过来想可能 C 语言中的 printf("hello world!\n"); 的底层就执行了这些指令
GDB 调试
在编写好上面的 hello world 后,以 hello.s 作为文件名,使用 as 命令对其汇编 as hello.s -g -o hello.o,使用 ld 命令链接 ld hello.o -g -o hello,其中 -g 表示使用 gdb 调试,之前没加上可能会找不到源文件
gdb test // 使用 gdb 调试 test
gdb test -q // -q(quite) 关闭 gdb test 的免责申明
break(b) _start // b/break 在 _start 处打断点
run // 运行程序到断点处
layout // 查看布局
layout regs // 查看所有寄存器
info register r0 // 查看单个寄存器
layout prev/next // 布局窗口切换
stepi(s) // 执行一条程序,若有函数调用则进入
next(n) // 执行一条程序,不进入调用函数内部
x/10x $r1 // 从 r1 值开始以 hex 形式查看 10 个内存地址
x/10d $r1 // 从 r1 值开始以 decimal 形式查看 10 个内存地址
x/10c $r1 // 从 r1 值开始以 char 形式查看 10 个内存地址
最后,再放上 azeria 制作的一览表,以便快速回顾一些 arm 汇编基本知识
