ARM CortexM
记录 ARM Cortex M3/M4 内部架构基础知识
学习笔记,仅供参考
参考:Udemy - 嵌入式系统编程 |
在简单了解 ARM 汇编之后,仍存在很多不解之处,所以就借着此课程了解 ARM Cortex M3/M4 架构基本知识
操作模式与访问级别
操作模式
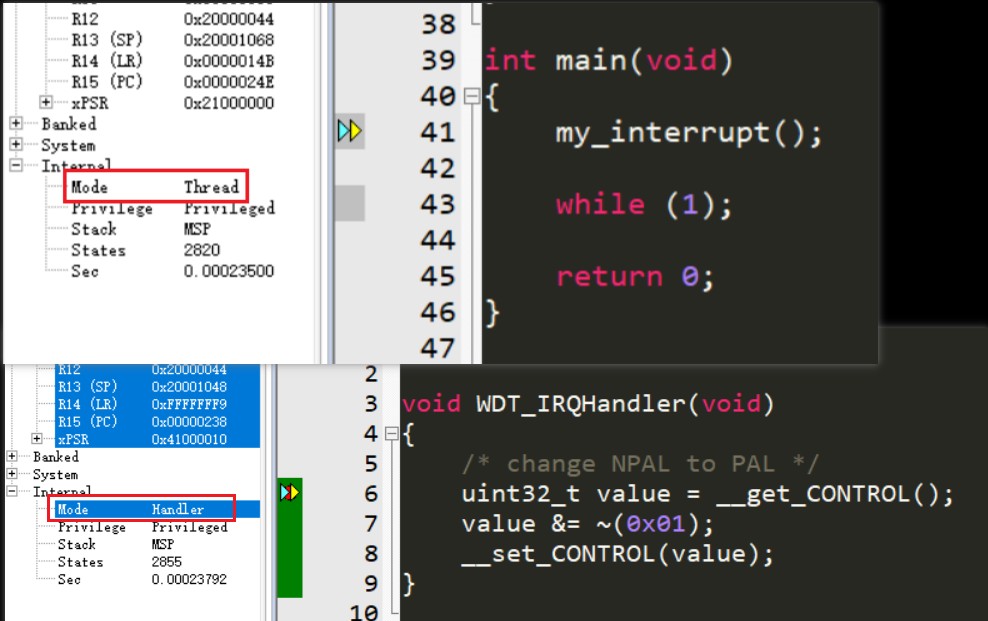
在 ARM Cortex 中存在两种操作模式:线程模式(Thread Mode) 和 处理模式(Handler Mode)
线程模式:用户编写的应用程序运行在此模式下,因此也叫“用户模式”
处理模式:所有的异常/中断处理程序均运行在该模式
另外,处理器总是以 Thread Mode 开始运行程序。一旦 ARM Core 遇到异常/中断就会变为 Handler Mode,并执行对应的 ISR(Interrupt Service Routine)
访问级别
同样,ARM Cortex 中也有两种访问级别(Access Level):特权级 和 非特权级(用户级)
特权级:PAL(Privileged Access Level),该级别下能够让处理器访问所有的资源和有限制的寄存器
非特权级(用户级):NPAL(Unprivileged Access Level),该级别下处理器不能够访问有限制的寄存器
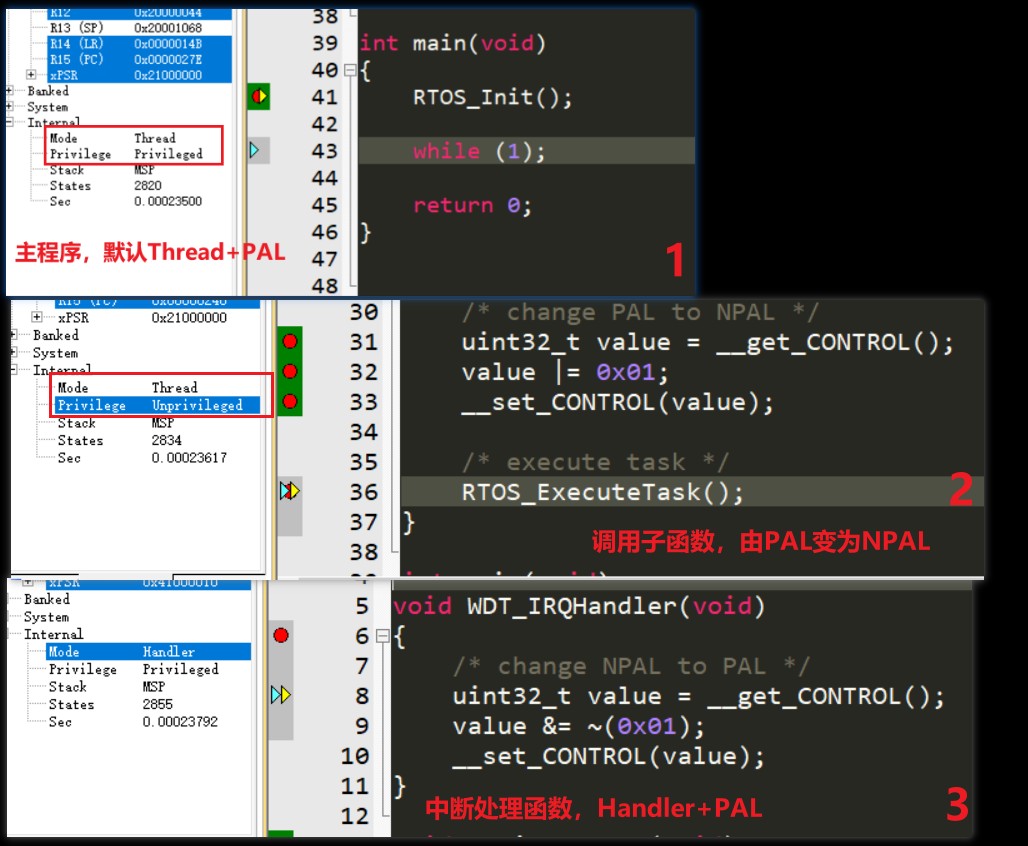
因此,操作模式+访问级别就有四种组合方式,但由于 Handler Mode 总是在 PAL 级别,故实际只有三种:Thread+PAL、Thread+NPAL、Handler+PAL
在 Thread Mode 下,默认为 PAL 级别,可通过向 CONTROL 寄存器的 bit[0] 写 ‘1’ 来改变为 NPAL 级别。又因为 NPAL 级别没法访问有限制寄存器,所有就不能再从 NPAL 级别下变回 PAL 级别
在 Handler Mode 下,总是 PAL 级别,因此 Thread+NPAL 只有进 Handler Mode 在处理异常中申请修改 CONTROL 才能回到 Thread+PAL
寄存器
通用寄存器
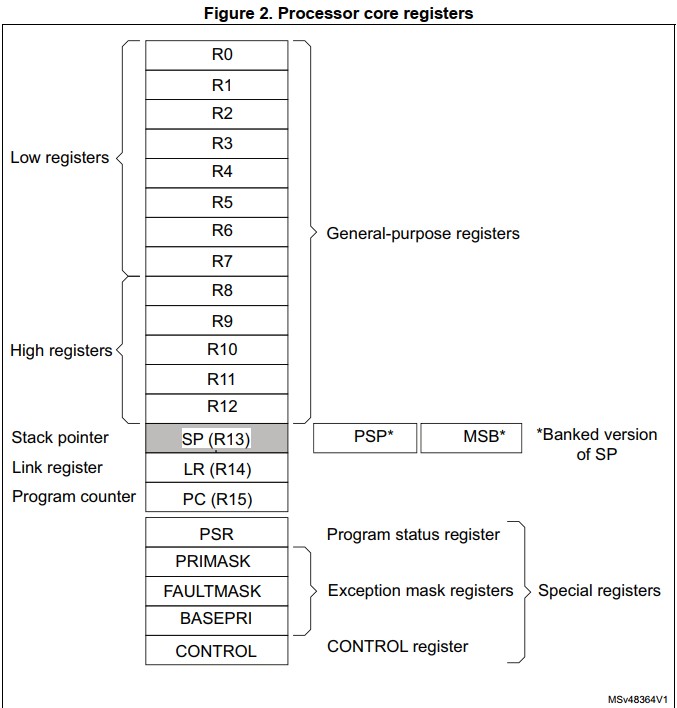
通用寄存器为 R0~R7 和 R8~R12,其中 R0~R7 也被称为 低组寄存器,所有指令都访问它们,它们字长全为 32 位,复位后的初始值随机;而 R8~R12 被称为 高组寄存器,因为只有很少的 16 位 Thumb 指令能够访问它们,32 位的 Thumb-2 指令则不受限制,同样字长也是 32 位,复位初始值随机。
SP(Stack Pointer)即 R13 寄存器,在 Thread Mode 下,寄存器 CONTROL 的 bit[1] 设置 SP 使用:
0:MSP(Main Stack Pointer),重置默认此类型
1:PSP(Process Stack Pointer)
当重置时,处理器会将地址 0x0000_0000 的值加载到 MSP 中
LR(Link Register)即 R14 寄存器,用于存储子函数、异常处理函数的返回地址,重置默认值为:0xffff_ffff
PC(Program Conter)即 R15 寄存器,它包含当前程序地址,bit[0] 总为 0,因为要保证指令获取为半字对齐。重置时,处理器会将地址 0x0000_0004 的值加载 PC 中
特殊寄存器
PSR(Program Status Register)程序状态寄存器,它由三个子状态寄存器组成:
APSR(Application Program Status Register)应用程序 PSR
IPSR(Interrupt Program Status Register)中断 PSR
EPSR(Execution Program Status Register)执行 PSR
通过 MRS/MSR 指令可对单个 PSR 访问或组合访问,访问两个时,可以是 “IAPSR、IEPSR、EAPSR”,当三合一访问时,应使用名字 “xPSR” 或 “PSR”
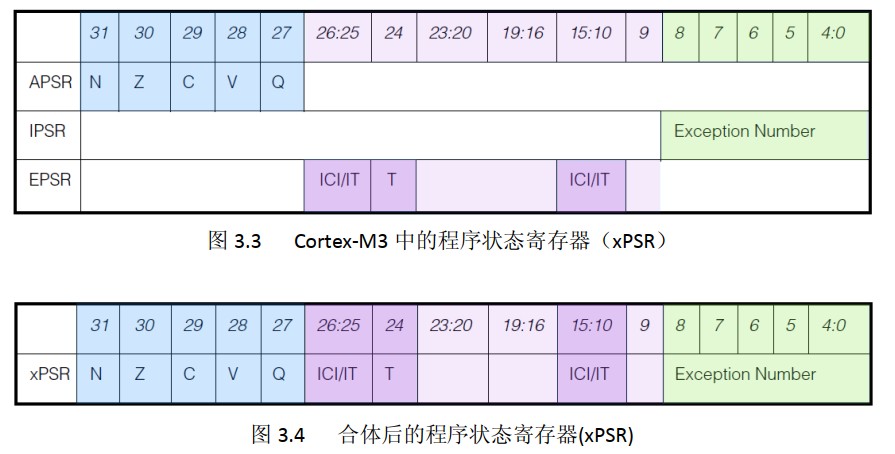
下面是对三个子寄存器的位功能描述:
APSR 包含指令执行后各条件标志的状态:
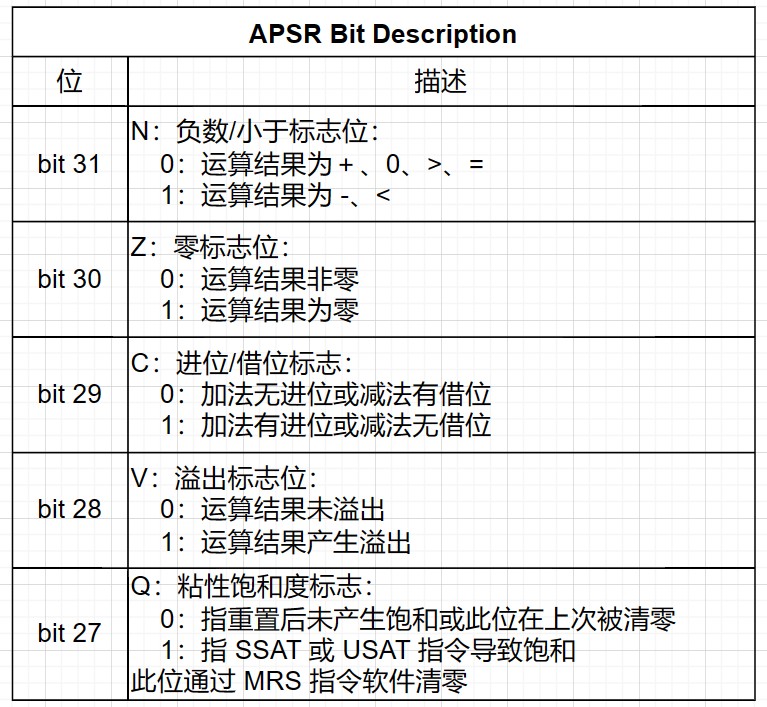
IPSR 包含当前中断服务函数(ISR, Interrupt Service Routine)对应的异常处理号码

EPSR 包含 Thumb 指令状态位:
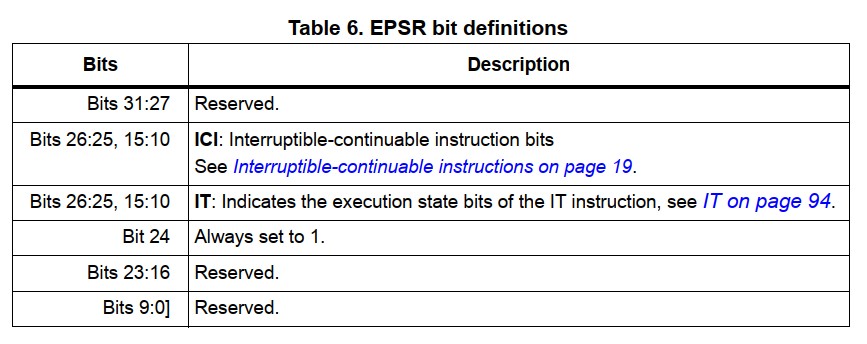
注意:EPSR 的 bit[24] ‘T’ 位:0 - 处理器会将下条指令当作 “ARM” 指令集执行;1 - 会当作 “Thumb” 指令集执行。由于 Cortex-M 处理器不支持 “ARM” 指令集,所以 ‘T’ 位总是为 1,若不为 1 将导致 “Usage fault” 异常。另外,PC 的 bit[0] 与 ‘T’ bit 关联,所以 PC 所取得值即 Vector address 均会被 +1 存放到对应内存中
Exception mask register 异常屏蔽寄存器,同样它也是由三个子寄存器组成:
PRIMASK:bit[0] 0 - 无作用;1 - 拒绝所有异常处理,除 NMI 和 hardfault 可以响应
FAULTMASK:bit[0] 0 - 无影响;1 - 拒绝除 NMI 以外的所有异常处理,包括 hardfault 也被屏蔽
BASEPRI:bit[7:4] 根据设置的优先级屏蔽异常,0x00 - 无作用;非零时拒绝处理 prority >= BASEPRI[7:4] 的异常
CONTROL 寄存器:控制处理器在 Thread Mode 下所使用的 SP 和 Access Level
bit[1]:0 - MSP;1 - PSP,在 Handler Mode 下该位为 0,即以 MSP 处理异常
bit[0]:0 - PAL;1 - NPAL
在 OS 中,推荐在 Thread Mode 下使用 PSP,在 Handler Mode 下使用 MSP。而默认 Thread Mode 使用的是 MSP,所以要使用 MSR 指令将 CONTROL[1] 设置为 1,即将 SP 从 MSP 改为 PSP。并且 MSR 指令之后必须要立即跟上 ISB 指令,确保在 ISB 执行后使用的是新的 SP
处理器重置过程
下面就简要描述处理器在按下复位后的一系列操作步骤:
将地址 0x0000_0000 装载到 PC 寄存器中
处理器读取地址 0x0000_0000 的值装载到 MSP 寄存器中
然后处理器从地址 0x0000_0004 读取到 reset handler 的地址,并装载到 PC
接着由 PC 让程序跳至 reset handler 开始执行对应的处理指令
在 reset handler 中调用 main() 函数,使程序开始执行所编写的代码指令
下面是在 Keil 中验证的截图
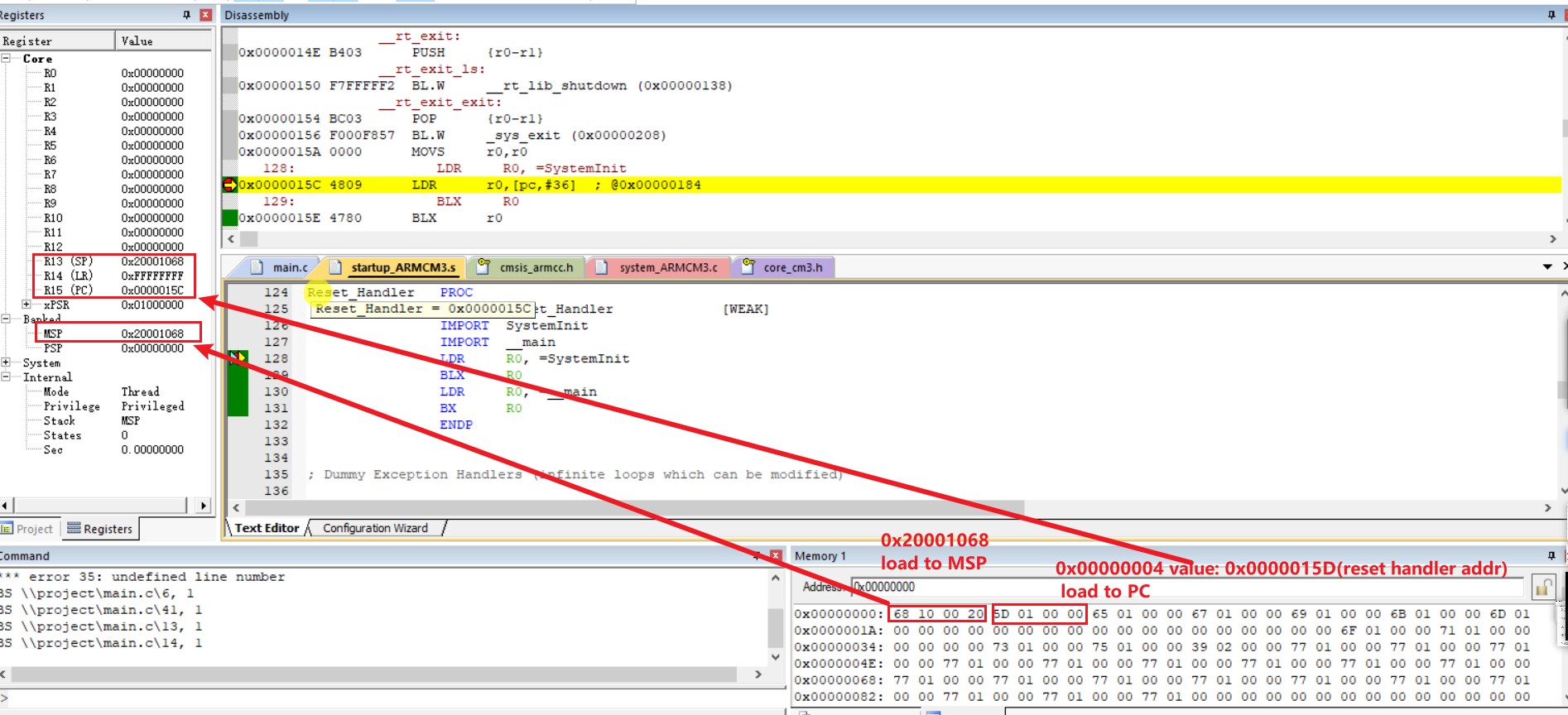
虽然看不到最开始将 0x00000000 装载到 PC 的过程,但从 PC 的值能看出它是从地址 0x00000000 开始执行的,并且 MSP 确实是地址 0x00000000 里的值 0x2000_1068,reset handler 也是地址 0x00000004 的值 0x0000_0015C+1,接着程序也跳至 reset handler 执行对应指令

然后又查看 reset handler(0x0000_015C) 对应的内存,能看到一开始是一些准备工作,而对应红色区域的第一个地址值是 SystemInit 对应的地址,第二个地址值是 main 对应的地址
内存模型(Memory Model)
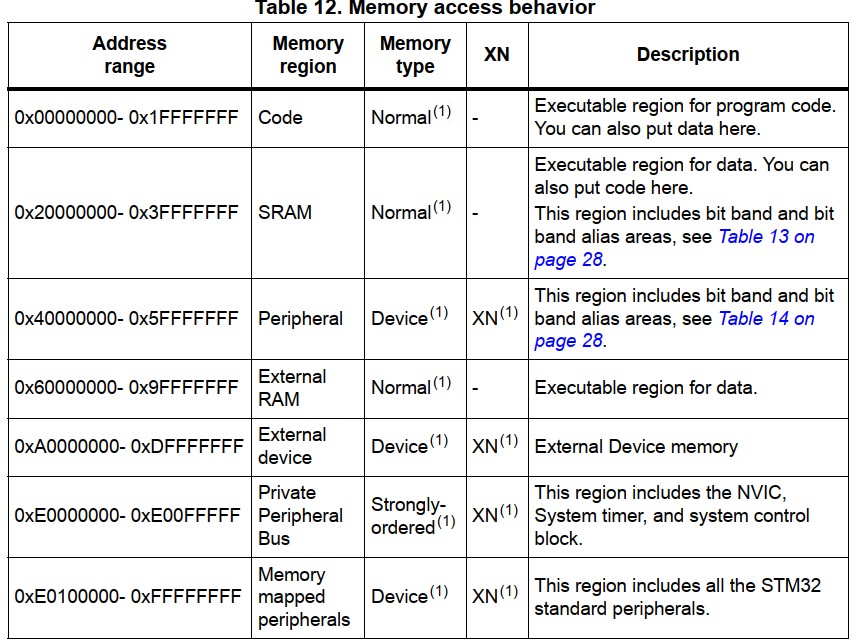
32 位的处理器拥有 4GB 的内存地址,下面就是对应的内存分布情况
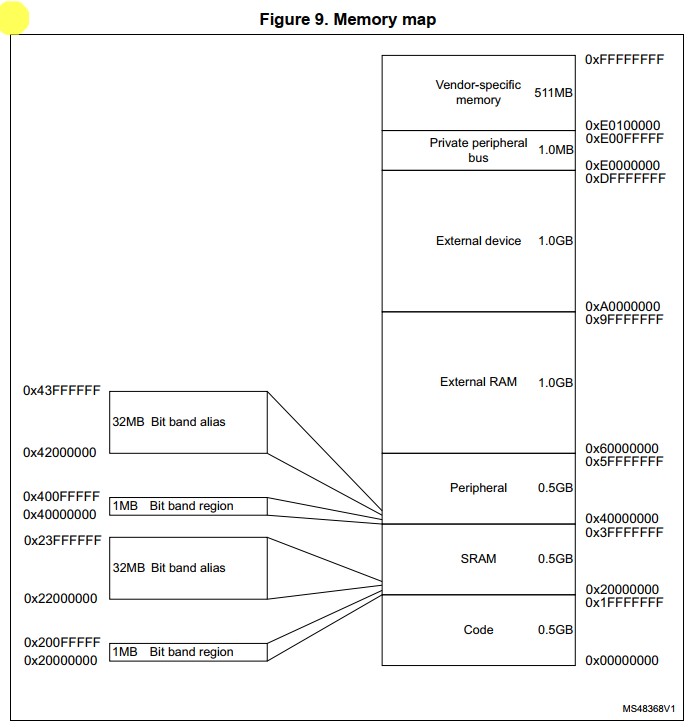
从内存分布图中就能看出,内存被分为不同的区域。每个区域都有一个定义好的内存类型(memory type),且一些区域还有额外的内存属性(memory attribute)
内存类型
常见的内存类型如下:
Normal(普通模式): 最常见的内存类型,用于存储数据、指令及其他类型的信息。所存数据能被缓存、预取和重排序
Device(设备模式):用于存储硬件设备的寄存器或设备控制器的缓冲区等。与 Normal 不同,Device 的数据不能被缓存、预取和重排序
Strongly-ordered(强序模式):特点就是对事务进行强序,当一个事务完成时,该事务之前的所有读写操作都必须在该事务之前完成。该内存类型常用于访问外设控制器、DMA 等需要确保数据正确性的场合
其中 SRAM 和 Peripheral 还拥有各自对应的 位带区域及别名,从图中 region 和 alias 的大小关系就能看出 alias 中使用 32bit 来表示 region 中的 1bit
处理器并不能总是保证程序执行顺序与对应内存事务保持一致,因为:一些内存类型(Normal)能对访问重排序来提高效率;处理器有多总线接口;不同区域有不同的等待状态;一些内存访问能被缓冲。因此,在一些对内存访问顺序有要求的场景,软件程序就必须包含 memory barrier instruction 来强制保证顺序,处理器所支持的 memory barrier instruction 如下:
DMB (Data Memory Barrier)指令保证未完成的内存事务在后续事务前完成
DSB (Data Synchronization Barrier)指令确保未完成的事务在后续事务指令执行前完成
ISB (Instruction Synchronization Barrier)指令确保所有已完成的内存事务能把后续指令所识别
下面是一些使用 barrier 指令的示例:
向量表(Vector table),若程序要改变向量中的数据并开启对应的异常,就要在两操作间使用 DMB 指令,保证异常在开启后就发生时,处理器能使用新的异常向量
自修改代码(Self-modifying code),若程序中包含自修改代码,则立即使用 ISB 指令,确保后续指令在执行时使用的是更改后的程序
内存映射转换(memory map switch),若系统包含内存映射转行机制,则在内存映射转换程序后使用 DSB 指令,保证后续指令执行用的是转换后的内存映射
动态异常优先级变换(Dynamic exception priority change),当异常处于等待或执行时要切换异常优先级,则在切换后使用 DSB 指令,确保异常优先级切换生效
位带
从上也了解到位带 region 和 alias 的关系,可以用公式来表示它们之间的换算
bit_word_offset = (byte_offset x 32) + (bit_num x 4) bit_word_addr = bit_band_base + bit+word_offset
这里,
- bit_word_offset 是 region 中的目标位;
byte_offset是在 region 中包含目标位的字节数;bit_num是目标位的第几位,0-7;bit_word_addr是 alias 中对应目标位的字地址bit_band_base是 alias 的起始地址/* 一些示例 */ /* region 中 0x2000_0000 的 bit[0] 对应 alias 的地址 */ addr = 0x22000000 + (0 * 32) + (0 * 4) = 0x22000000 /* region 中 0x2000_0000 的 bit[7] 对应 alias 的地址 */ addr = 0x22000000 + (0 * 32) + (7 * 4) = 0x2200001C /* region 中 0x200F_FFFF 的 bit[0] 对应 alias 的地址 */ addr = 0x22000000 + (0xFFFFF * 32) + (0 * 4) = 0x23FFFFE0 0010 0010 0000 1111 | 1111 1111 1111 1111(0x220FFFFF) 0010 0011 1111 1111 | 1111 1111 1110 0000(0x23FFFFE0) /* region 中 0x200F_FFFF 的 bit[7] 对应 alias 的地址 */ addr = 0x22000000 + (0xFFFFF * 32) + (7 * 4) = 0x23FFFFFC
从下边的映射图中更加清晰地感受这种映射关系
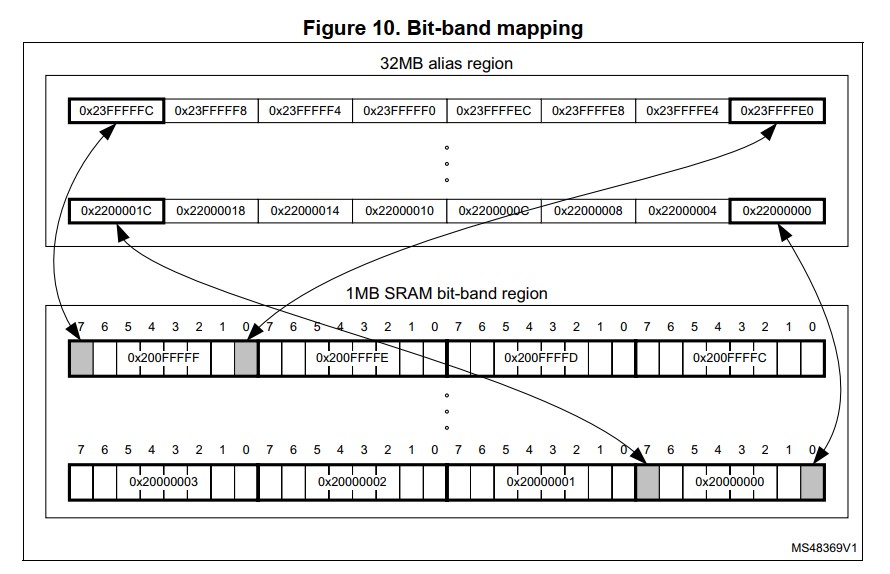
当使用位带完成读写操作时,只需关注 alias 地址对应数据的最低为 bit[0] 即可,而 bit[31:1] 对目标位没有影响。向目标位写 0,只需向对应位带写 0x0000_0000;向目标位写 1,只需向位带位写 0x0000_0001。同理,若从位带位读取到 0x0000_0000 说明目标位已置 0;读取到 0x0000_0001 说明目标位已置 1
总线协议
AHB(main system bus),在 M3 中 AHB 作为主总线接口,AHB 代表 AMBA High Performance Bus,此次 AMBA 指 Advanced Microcontroller Bus Architecture
APB(peripheral bus),它是用来减小功耗和降低接口复杂度,通常 APB 要比 AHB 更慢同时也更简单
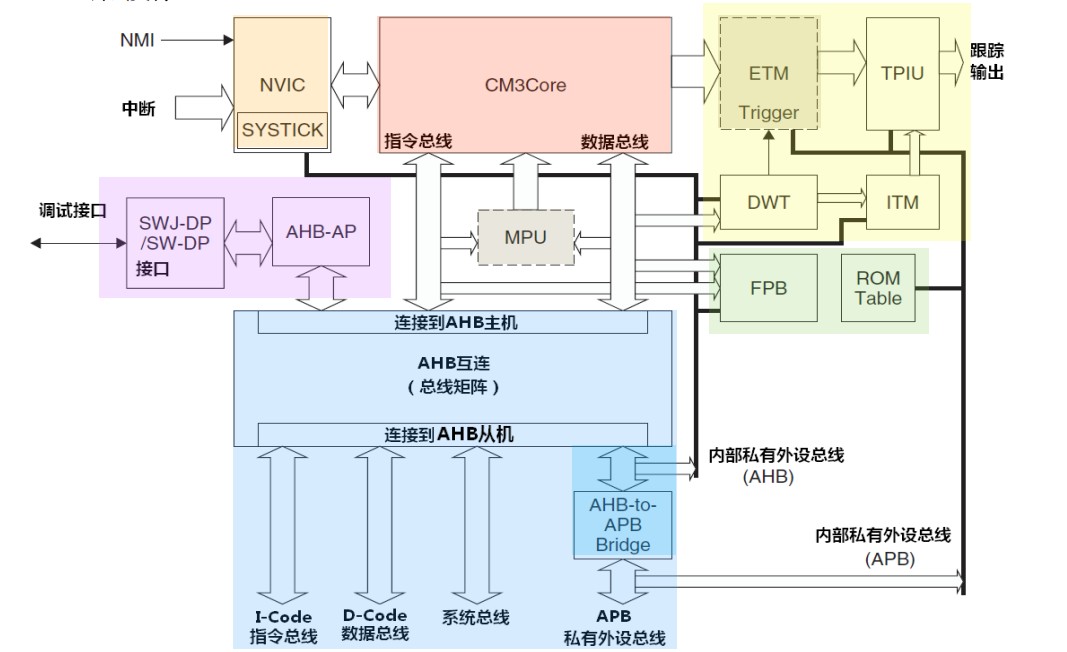
从结构图中能看出,内部访问数据或指令大多以 AHB 来传输,而访问外设时要通过 AHB-to-APB-Bridge 转为 APB 与内核以外的外设通信。特别地,I-code 是从 Code 区获取指令,它必须是数据对齐的,而 D-code 可以非数据对齐来获取 SRAM 的数据
数据对齐
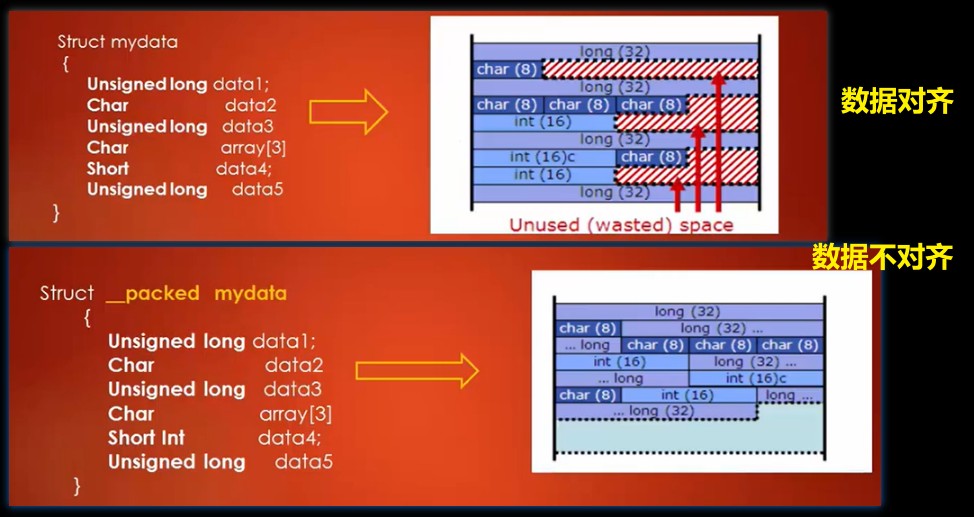
数据对齐,指数据按字节倍数的形式保持对齐,这样数据中会浪费一些空间,但这对总线传输来说就比较友好
数据非对齐,指数据紧密存储不留空隙,但在传输时仍会先转为数据对齐的形式,这样就会浪费一些时钟
因此,数据对齐与否是时间与空间之间的考量,若对性能效率要求较高的场景,就要用数据对齐;而对性能要求不高时就可用数据非对齐
栈内存模型
栈是一种保存数据的内存模型,通过 后进先出 的方式来暂存数据,常用其来存放局部变量、函数执行所需数据、函数返回值等。ARM 处理器利用 PUSH 将数据压入栈中,用 POP 指令将数据从栈中弹出,并且所有的栈操作均是字对齐的
在 Cortex-M3 中栈指针通常分两种:MSP(Main Stack Pointer) 和 PSP(Process Stack Pointer)。MSP 为重置后默认的栈指针,用于所有的异常处理,上电后处理器会自动从向量表中读取数据装载到 MSP 中;PSP 只能用于 Thread Mode,上电后并不会将其初始化,使用前必须通过软件初始化。另外,前文已提到可以通过 CONTROL 的 SPSEL 位来设置栈指针
当调用函数时,R0-R3 会作为参数传递,如下表所示。当然也会将 R4-R11、R13、R14 的内容压入栈中,保护现场,防止调用前的数据被子函数覆盖
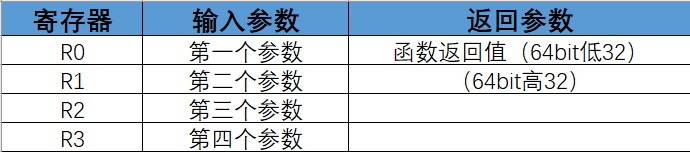
下图是函数调用时压栈与出栈操作对应内存的变化
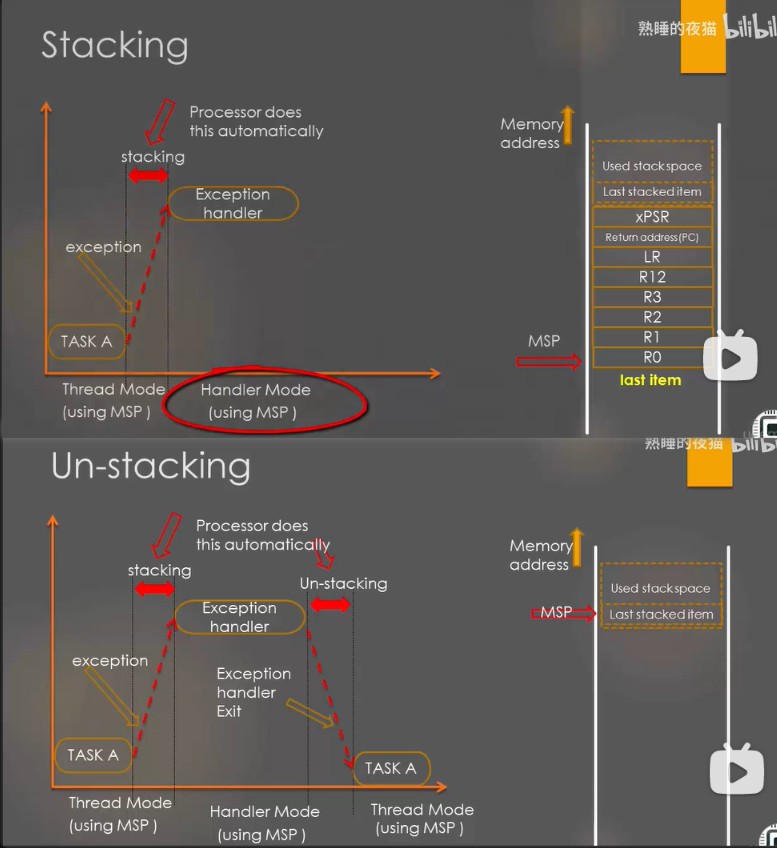
下面是一段 C 语言调用汇编栈操作函数的代码
/* main.c */
#include "ARMCM3.h"
// include assembly function
extern void do_stack_operation(void);
int main(void)
{
do_stack_operation(); // call assembly func
return 0;
}
/**************************************/
/* stack_op.s */
AREA STACK_OP, CODE, READONLY
EXPORT do_stack_operation
do_stack_operation
MOV R0, #0x11 // init R0-R2
MOV R1, #0x22
MOV R2, #0x33
PUSH {R0-R2} // push R0-R2 to stack
MRS R0, CONTROL // set CONTROL SPSEL bit
ORR R0, R0, #0x02 // MSP -> PSP
MSR CONTROL, R0
MRS R0, MSP // assign MSP value to PSP
MSR PSP, R0
POP {R0-R2} // POP R0-R2 from stack
BX lr // return
END
异常
异常 指来自外部世界或内部系统的事件发生,当异常生成时处理器从正常的程序转到异常服务程序。因此任何能打断正常程序的东西都可称为“异常”
另外中断也属于外部世界(相对于处理器而言)产生的异常,例如:定时器中断、IIC、USART、GPIO 等等
按照定义可将异常分为两类:系统异常和外部异常
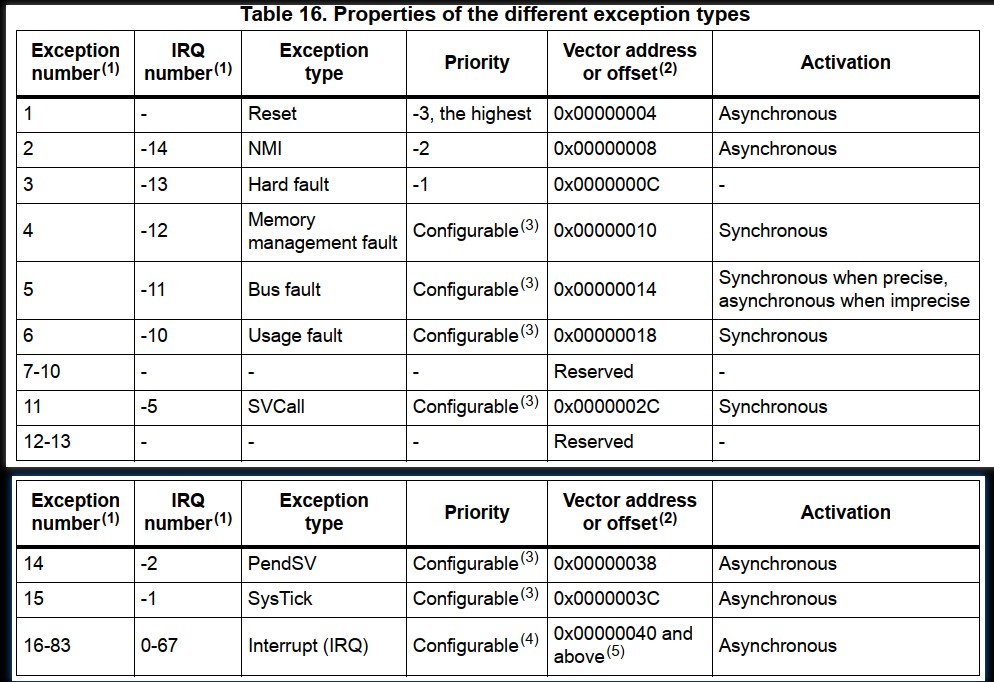
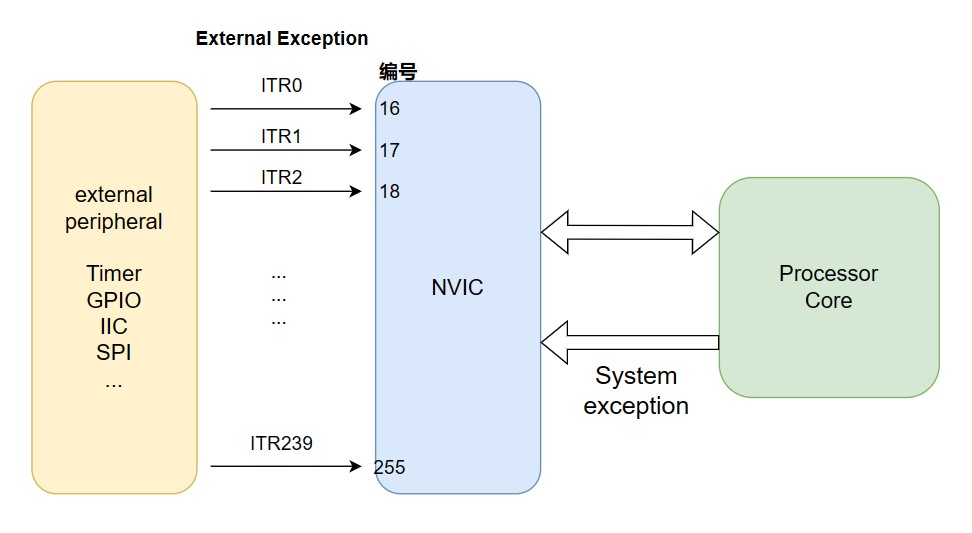
系统异常,为处理器内部系统所产生的异常,如 reset、hardfault 等。总共有 15 种,异常号是从 1 到 15
外部异常(中断),为处理器外部外设所产生的异常,如 Timer、GPIO 等。总共有 240 种,异常号从 16 到 255
下面就简要了解下系统异常有哪些
Reset,该异常在上电或复位时调用,复位使能后处理器会停止一切操作,复位失能后处理器从向量表的 Reset 入口地址重新执行程序(execution restart),且必须在 Thread Mode PAL,Reset 优先级为 -3(最高)
NMI,NonMaskable Interrupt 可有外设或软件触发,除了 Reset 它有最高优先级(-2),NMI 不可关闭
Hard fault,当异常处理出错或异常不能被管理时就会触发 HardFault,优先级为 -1
Memory management fault,当有关内存保护错误时会触发此异常,常用于保护那些不可执行的内存区域被访问
Bus fault,当有关指令或数据内存事务处理错误时会触发,因为它可能在总线上被检测到,所以称 Bus fault
Usage fault,当有关指令错误时触发,包括:未定指令、非法的非对齐访问、指令执行无效、异常返回错误
SVCall,supervisor call 异常由 SVC 指令触发,在 OS 中应用可用 SVC 指令访问 OS 内核函数和设备驱动程序
PendSV,是一种中断驱动请求,用于请求系统级服务程序,在 OS 中当没有其他异常执行时,可用 PendSV 做上下文切换(即任务切换、进程切换)
SysTick,当系统定时器归零时就会产生此异常,当然也能由软件生成,在 OS 中处理器能用其作为系统时钟(时间切片)
NVIC
NVIC(Nested Vector Interrupt Controler)嵌套向量中断控制器,Cortex-M 中有许多用来管理中断的可编程寄存器,而这些寄存器大多在 NVIC 中。一般有两种方式控制和管理中断,一种是直接访问 NVIC 寄存器(只能在 PAL 下);另一种是使用 CMSIS 所提供的 API 间接访问。在 reset 后所有中断都被失能,且中断优先级也被置 0,所以要想使用所需中断要设置所请求中断的优先级(可选),在 NVIC 中断使能寄存器中开启该中断(必须)。当中断触发时,处理器就会执行相应的 ISR,且 ISR 可在 Startup 文件中找到。
中断优先级,在 Cortex-M 中高优先级先于低优先级执行,而 reset、NMI、hardFault 优先级固定且为最高的三个,优先级数越小的优先级越高。
另外,软件配置中断优先级的数值在 0-15 范围内。例如 IRQ[0] 优先级为 15,IRQ[1] 优先级为 0 时,会先执行 IRQ[1]。若有多个处于等待中的异常,且它们优先级相同,那么就会先从异常号小的异常执行,如 IRQ[0] 与 IRQ[1] 优先级相等且都处于等待中,那么会先执行 IRQ[0]。当处理器在处理异常时遇到更高优先级的异常,那么此异常就会被抢占等高优先级异常处理完后接着执行,若遇到相同优先级的异常,那此异常就不会被抢占,新的异常会处于等待状态。
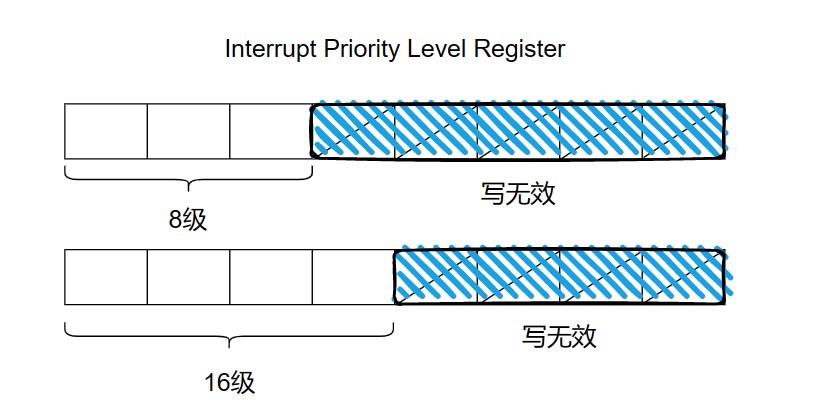
中断优先级寄存器,用于设置不同中断的优先级,下图是中断优先级的寄存器,由于不同 microcontroller 有不同的中断优先级寄存器,所以可配置的中断优先级范围就不同
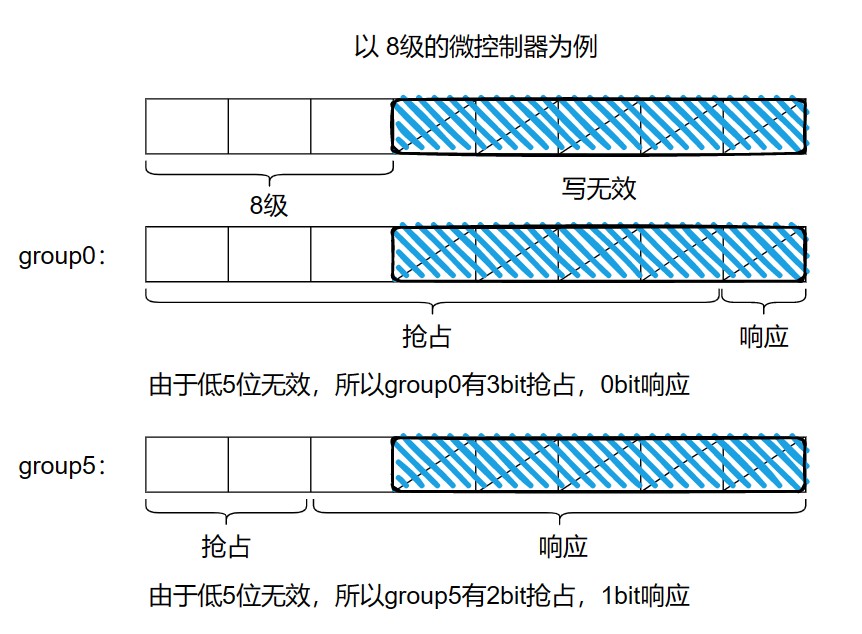
中断优先级分组,为加强系统中断优先级控制,NVIC 提供了优先级分组,它将中断优先级寄存器的有效位分为两部分:group priority(较高位) 和 *subpriority(较低位)*。只有 group priority 决定中断是否被抢占,因此它也被称为 抢占优先级,而 subpriority 决定有相同抢占优先级且处于等待状态的中断被先处理的顺序,所以它被称为 响应优先级/子优先级,要是抢占和响应都相同时就按照中断号从小到大执行
AIRCR(地址: 0xE000_ED00)应用程序中断及复位控制寄存器的 bit[10:8] 设置优先级分组,3 位可设置 8 组,默认为 group0 ,下面就演示 不同分组对应的抢占优先级和响应优先级
/* NVIC 相关 API */
void NVIC_SetPriorityGrouping(uint32_t group); // group:0-7
void NVIC_GetPriorityGrouping(void);
void NVIC_EnableIRQ(IRQn_Type IRQn); // 开指定 IRQ
void NVIC_DisableIRQ(IRQn_Type IRQn); // 关指定 IRQ
uint32_t NVIC_GetEnableIRQ(IRQn_Type IRQn); // 检查 IRQ 是否开启,0 关 1 开
uint32_t NVIC_GetPendingIRQ(IRQn_Type IRQn); // 检查 IRQ 是否处于 Pending,0 否 1 是
void NVIC_SetPendingIRQ(IRQn_Type IRQn); // 将指定 IRQ 设为 Pending
void NVIC_ClearPendingIRQ(IRQn_Type IRQn); // 清除指定 IRQ Pending
异常中断向量表 包含 MSP 初始值、系统异常和中断的处理地址。向量表偏移量寄存器(VTOR, Vector Table Offset Reg)地址 0xE000_ED08 其必须要写值,让向量表偏移到不同的内存区域。
异常处理的开始与返回过程
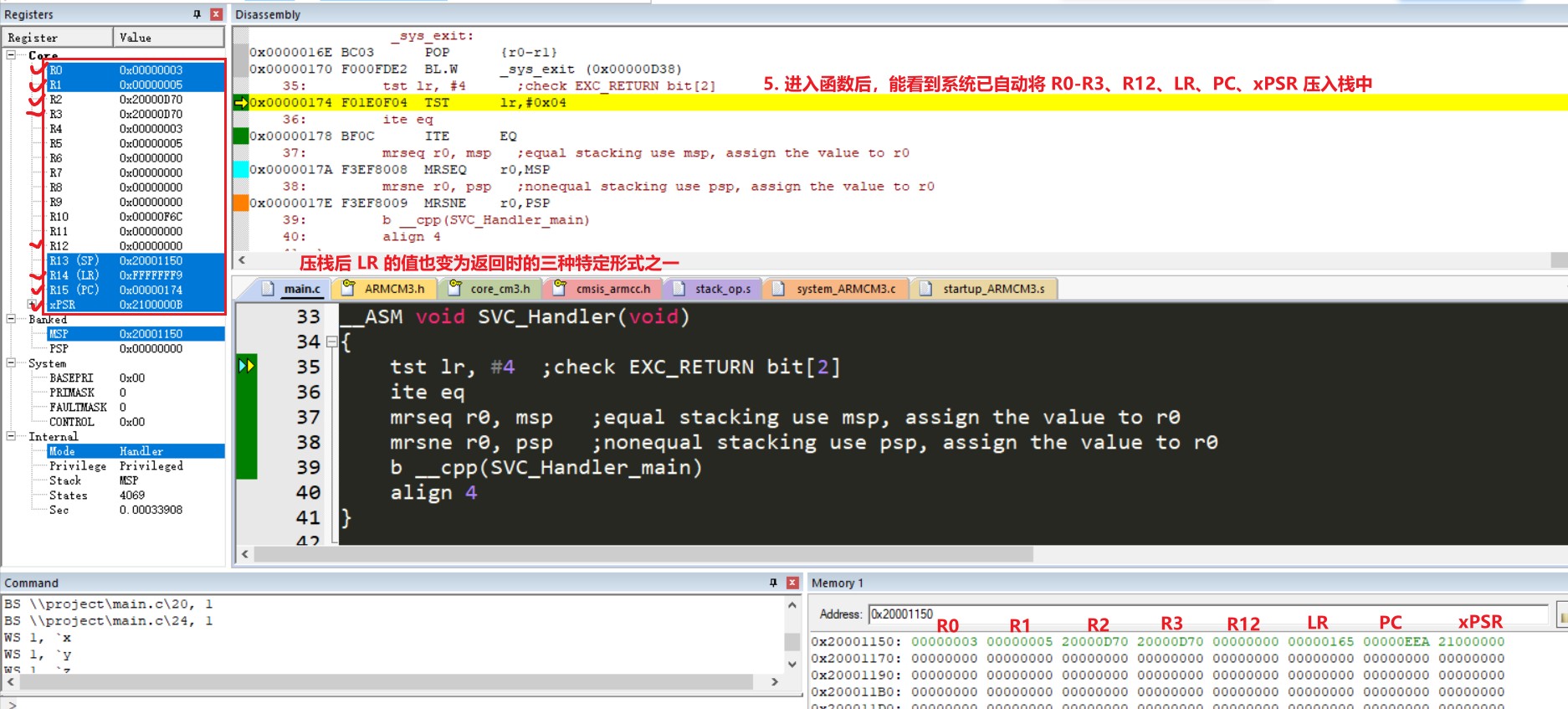
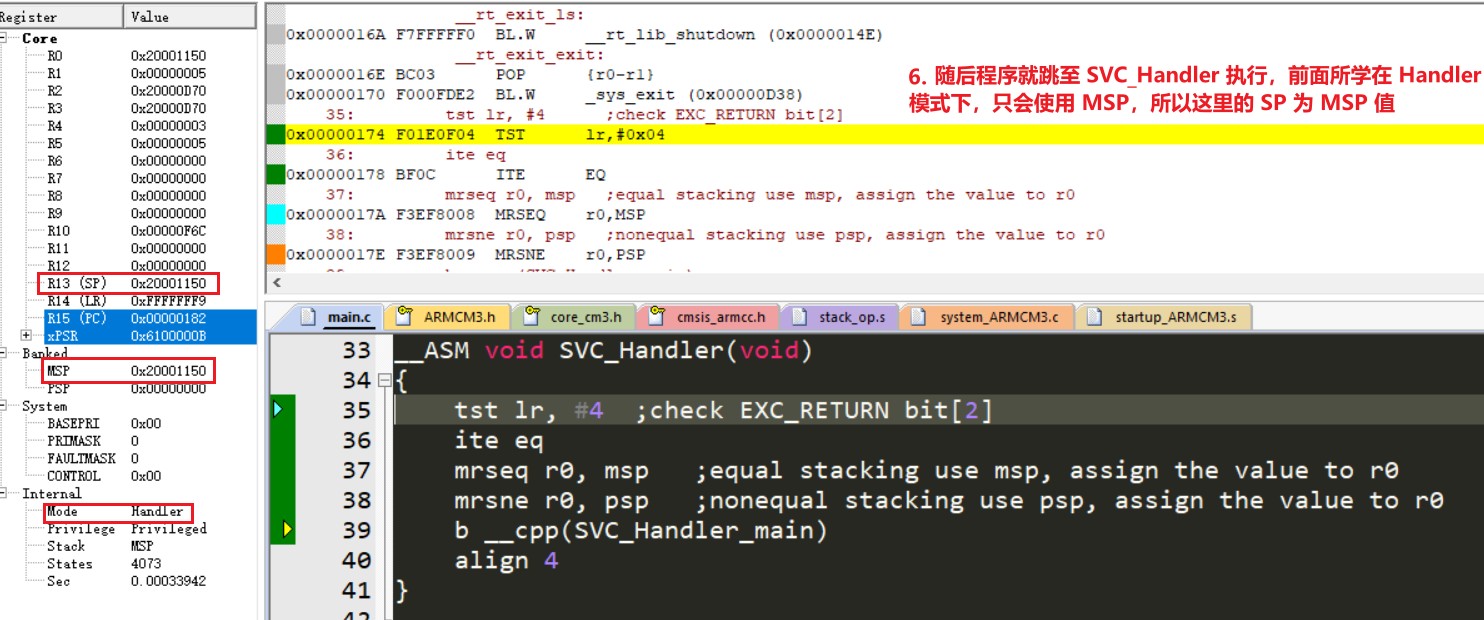
起始过程:当处理器执行异常时,会将信息压入当前栈,而信息指的就是 8 字大小的数据结构也叫做 *栈帧*。栈帧包含如下信息:R0-R3, R12, Return address, PSR, LR,且在压栈之后栈指针会指向栈帧的最低地址。Return address 就是异常程序的下条指令的地址,当异常返回时会将此值重载到 PC,以达到异常处理后继续执行异常之后的程序。
在压栈的同时处理器会从向量表中读取异常处理的起始地址,当压栈完成后处理器就会开始异常处理,与此同时处理器将 EXC_RETURN 值写入 LR 中。若在异常开始过程没有更高优先级的异常产生,处理器就会开始执行异常处理程序并自动将对应 Pending interrupt 的状态改为 Active。若有更高优先级异常产生,处理器会执行新异常的异常处理,且不会将原先异常的 Pending interrupt 状态改为 Active
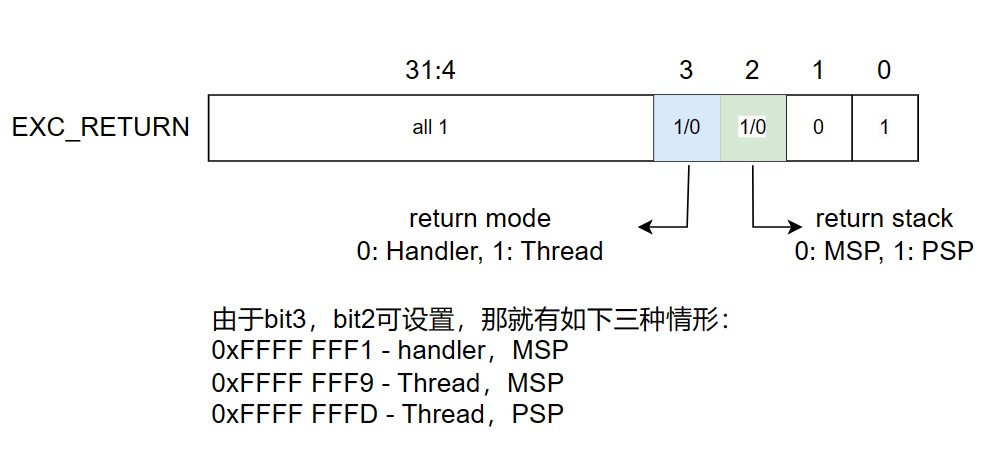
返回过程:当处理器处于 Handler Mode 并执行如下指令将 EXC_RETURN 值载入到 PC 时就会触发异常返回,指令为:POP include PC, BX with any reg, LDR or LDM with PC as destination。EXC_RETURN 为异常起始载入到 LR 的值,bit[31:4] 全为 1,后四位包含了异常返回后栈类型和处理器模式信息,如下图所示
SVC 与 PendSV
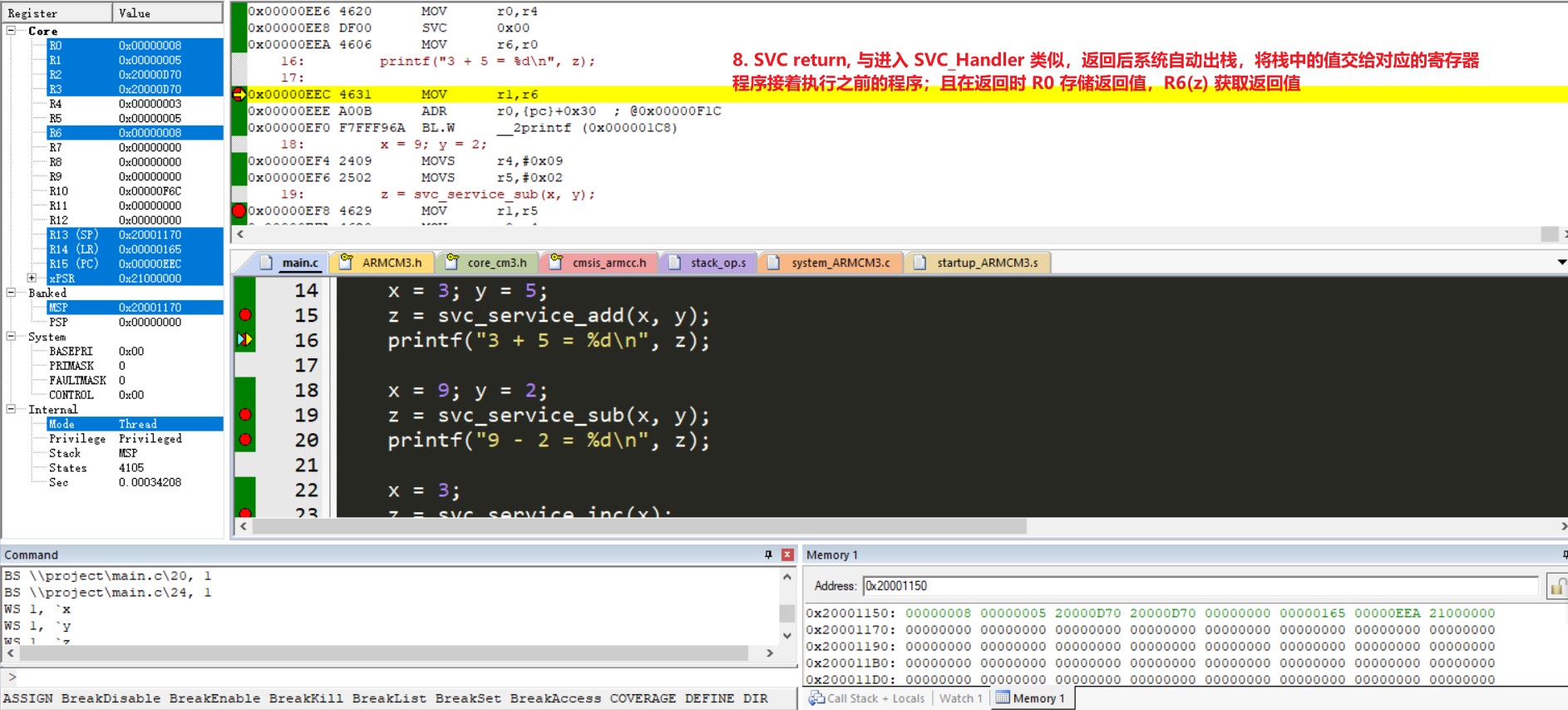
SVC,从异常分类中就已了解到它是一种请求系统异常,由 SVC 指令触发。SVC 指令需要一个立即数来充当系统调用的服务号,在 SVC 异常处理中会将将此服务号取出,从而知悉此次要调用何种服务函数
SVC 0x00 // 即使用汇编指令 SVC 调用服务号为 0x00 的程序
/* 由于 SVC 是向系统请求异常处理,所以为了让处理的速度更快,
* 系统会硬件自动完成 SVC 服务函数的入栈和出栈操作。 */在 ARM 指令学习中遇到了 SWI 软中断指令,其实 SVC 和 SWI 都是向系统申请异常处理,只是因为 ARM 处理器系统不同叫法不同而已,功能还是一样的
另外需注意,不能在 SVC 服务函数中嵌套使用 SVC 指令,这样只会产生一个 Usage fault。同理,在 NMI 服务函数中也不能使用 SVC,否则会触发 Hard fault
下面看一个代码例程体验下这种调用 SVC 请求服务函数的过程,本代码参考自bilibili - 大智工作室,其参考书籍《ARM Cortex M3 和 M4 权威指南》- 第十章 SVC 结尾处的代码示例
#include "ARMCM3.h" // Device header
#include <stdio.h>
/* 定义 SVC 函数 */
int __svc(0x00) svc_service_add(int x, int y); // service #0
int __svc(0x01) svc_service_sub(int x, int y); // service #1
int __svc(0x02) svc_service_inc(int x); // service #2
void SVC_Handler_main(unsigned int * svc_args); // SVC Handler main code
/* main 函数 */
int main(void)
{
int x, y, z;
x = 3; y = 5;
z = svc_service_add(x, y);
printf("3 + 5 = %d\n", z);
x = 9; y = 2;
z = svc_service_sub(x, y);
printf("9 - 2 = %d\n", z);
x = 3;
z = svc_service_inc(x);
printf("3++ = %d\n", z);
while (1);
return 0;
}
/* SVC Handler function */
__ASM void SVC_Handler(void)
{
tst lr, #4 ;check EXC_RETURN bit[2]
ite eq
mrseq r0, msp ;equal stacking use msp, assign the value to r0
mrsne r0, psp ;nonequal stacking use psp, assign the value to r0
b __cpp(SVC_Handler_main)
align 4
}
/* SVC_Handler_main */
void SVC_Handler_main(unsigned int * svc_args)
{
// stack frame contain: r0, r1, r2, r3, r12, lr, return_address(pc), xPSR
// r0 = svc_args[0]; r1 = svc_args[1]; r2 = svc_args[2];
// r3 = svc_args[3]; r12 = svc_args[4]; lr = svc_args[5];
// pc = svc_args[6]; xPSR = svc_args[7];
unsigned int svc_number;
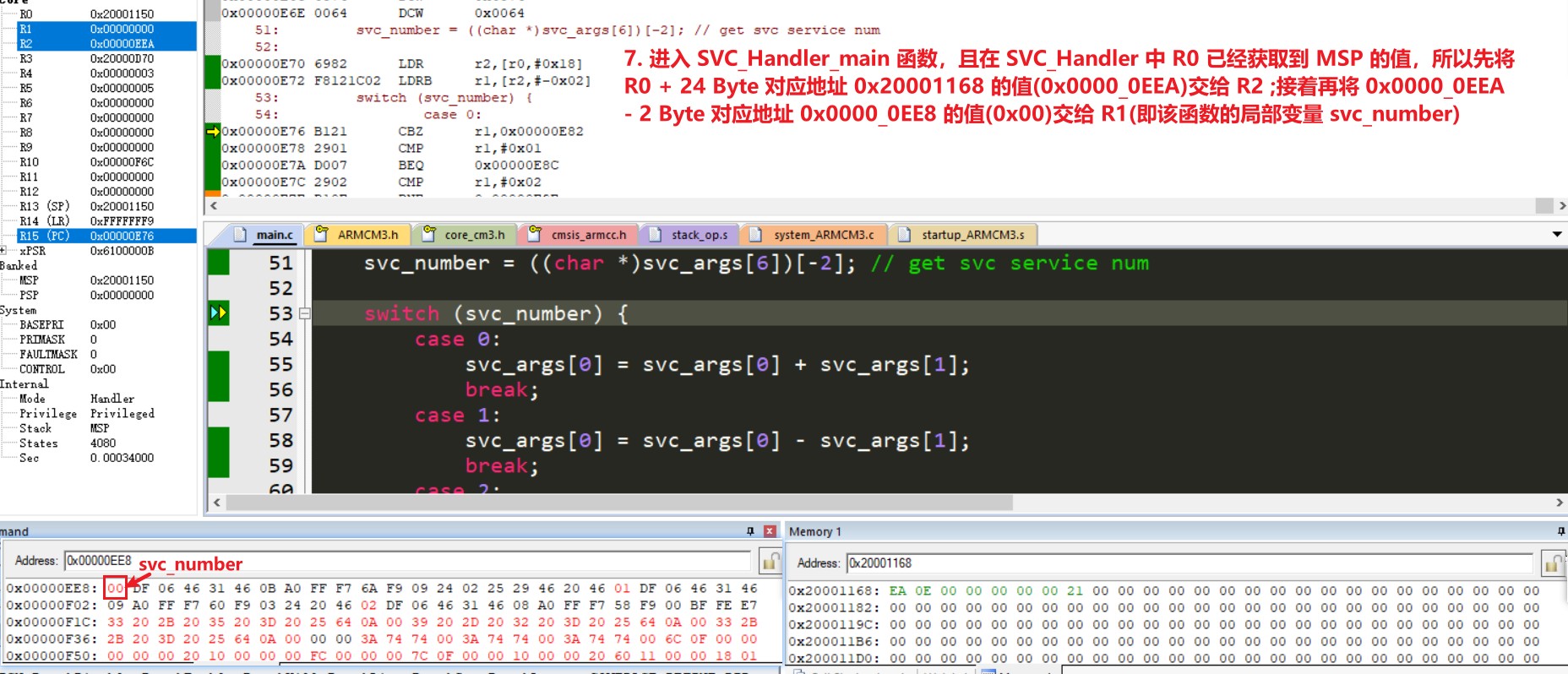
svc_number = ((char *)svc_args[6])[-2]; // get svc service num
switch (svc_number) {
case 0:
svc_args[0] = svc_args[0] + svc_args[1];
break;
case 1:
svc_args[0] = svc_args[0] - svc_args[1];
break;
case 2:
svc_args[0] += 1;
break;
default:
break;
}
}虽然程序并未具体定义 svc_service_add(int x, int y) 等函数,但由于在声明时加上 __svc(0x00) 表明调用该函数就等价于汇编里的 SVC 0x00,即程序就会进入 SVC_Handler(void) 执行服务函数。在自定义的 SVC_Handler_main(unsigned int *svc_args) 中通过获取当前的服务号进行不同的操作
svc_number = ((char *)svc_args[6])[-2];
/* 这行代码是为获取服务号,根据函数声明可知 svc_args 为 unsigned int * 类型
* 即 svc_args 为 4 字节指针变量,所以 svc_args[6] 为 svc_args+6 地址所存的值,
* 再由强转 (char *) 将数字变量变为指针变量且指针步距变为 1 字节,[-2] 表示
* 将 svc_args[6] 数值对应地址再左偏 2 字节地址的值赋给 svc_number
* (还是第一次见到这种指针操作,太强了) */接着用 Keil 仿真调试这一过程

PendSV
PendSV 异常,用于多任务上下文切换,该异常属于系统异常且可对其优先级编程,一般会将其优先级设置为最低,由 “Interrupt control and state reg” 的 Pending status 来触发此异常。
用法:通常在高优先级的异常处理函数中触发 PendSV 异常,等高优先级异常处理完成后执行所触发的 PendSV 异常处理函数。通过此方法就能在 OS 所有任务中断完成后,执行 PendSV 切换任务,这就是 OS 切换上下文的关键。
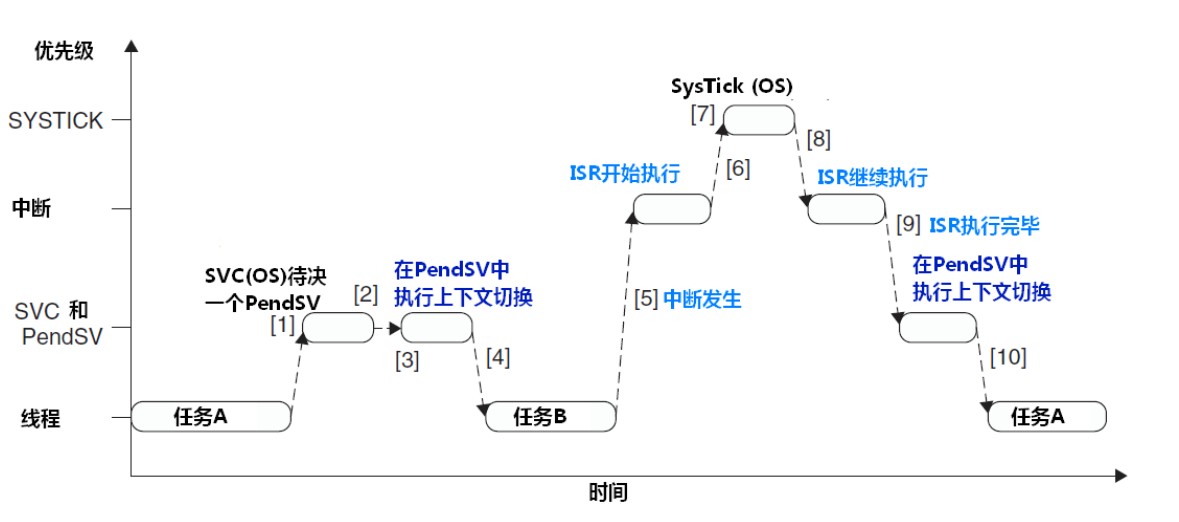
任务 A 发起 SVC 请求来切换任务
OS 收到请求后,做好上下文切换的准备,并触发 PendSV 异常
当处理器从 SVC 返回后,立即进入 PendSV 异常处理,从而执行上下文切换程序
当 PendSV 返回后表明完成任务切换,处理器开始执行任务 B,并进入 Thread Mode
发生中断,处理器从任务 B 进入 ISR 处理函数中
在 ISR 中由发生 SysTick 异常,并抢占该 ISR
OS 执行必要操作,然后触发 PendSV 异常已做好上下文切换的准备
当 SysTick 异常返回后,继续执行被抢占的 ISR
ISR 返回后,进入 PendSV 异常处理,完成上下文切换
当 PendSV 结束返回后,程序开始执行任务 A,并进入 Thread Mode
同样以一个程序例程体会 PendSV 是如何用来切换上下文的,本代码也参考自bilibili - 大智工作室
#include "ARMCM3.h" // Device header
#include <stdio.h>
#define HW32_REG(ADDRESS) (*((volatile unsigned long *)(ADDRESS)))
/* define task */
uint8_t flag0, flag1, flag2, flag3;
void task0(void);
void task1(void);
void task2(void);
void task3(void);
/* task event */
volatile uint32_t systick_count = 0;
/* task stack - each stack size: 512B(128 * 8) */
long long task0_stack[128], task1_stack[128],
task2_stack[128], task3_stack[128];
/* OS using data */
uint32_t curr_task = 0; // current task
uint32_t next_task = 1; // next task
uint32_t PSP_array[4]; // each task psp stack pointer
/* main 函数 */
int main(void)
{
SCB->CCR |= SCB_CCR_STKALIGN_Msk; // enable daul-word stack align
/* start scheduler */
// create task0 stack frame
PSP_array[0] = ((unsigned int)task0_stack) + (sizeof task0_stack) - 16 * 4;
HW32_REG((PSP_array[0] + (14 << 2))) = (unsigned long)task0;
// initialize program count
HW32_REG((PSP_array[0] + (15 << 2))) = 0x01000000; // init xPSR
// create task1 stack frame
PSP_array[1] = ((unsigned int)task1_stack) + (sizeof task1_stack) - 16 * 4;
HW32_REG((PSP_array[1] + (14 << 2))) = (unsigned long)task1;
// initialize program count
HW32_REG((PSP_array[1] + (15 << 2))) = 0x01000000; // init xPSR
// create task2 stack frame
PSP_array[2] = ((unsigned int)task2_stack) + (sizeof task2_stack) - 16 * 4;
HW32_REG((PSP_array[2] + (14 << 2))) = (unsigned long)task2;
// initialize program count
HW32_REG((PSP_array[2] + (15 << 2))) = 0x01000000; // init xPSR
// create task0 stack frame
PSP_array[3] = ((unsigned int)task3_stack) + (sizeof task3_stack) - 16 * 4;
HW32_REG((PSP_array[3] + (14 << 2))) = (unsigned long)task3;
// initialize program count
HW32_REG((PSP_array[3] + (15 << 2))) = 0x01000000; // init xPSR
/* end sheduler */
curr_task = 0; // switch to task0
__set_PSP((PSP_array[curr_task] + 16*4)); // set PSP to top of task0 stack
NVIC_SetPriority(PendSV_IRQn, 0xFF); // set PendSV to lowest priority
SysTick_Config(72000); // 1KHZ SysTick Interrupt on 72MHZ core clock
__set_CONTROL(0x3); // switch to PSP and NPAL
__ISB(); // immediately execute ISB after changing CONTORL
task0(); // start task0
while (1);
return 0;
}
void task0(void)
{
while (1) {
if (systick_count & 0x80) flag0 = ~flag0;
}
}
void task1(void)
{
while (1) {
if (systick_count & 0x100) flag1 = ~flag1;
}
}
void task2(void)
{
while (1) {
if (systick_count & 0x200) flag2 = ~flag2;
}
}
void task3(void)
{
while (1) {
if (systick_count & 0x400) flag3 = ~flag3;
}
}
/* SysTick Handler function */
void SysTick_Handler(void)
{
systick_count++;
switch (curr_task) {
case 0:
next_task = 1;
break;
case 1:
next_task = 2;
break;
case 2:
next_task = 3;
break;
case 3:
next_task = 0;
break;
default:
next_task = 0;
while(1);
break;
}
if (curr_task != next_task) { // set PendSV
SCB->ICSR |= SCB_ICSR_PENDSVSET_Msk;
}
}
/* PendSV Handler function */
__ASM void PendSV_Handler(void)
{
/* context switching code */
// save current context
mrs r0, psp // get current psp value
stmdb r0!, {r4-r11} // save R4 to R11 in task stack
ldr r1, =__cpp(&curr_task)
ldr r2, [r1] // load curr_task value to r2
ldr r3, =__cpp(&PSP_array)
str r0, [r3, r2, lsl #2]// save PSP value into PSP_array
// load next context
ldr r4, =__cpp(&next_task)
ldr r4, [r4] // get next task value
str r4, [r1] // set curr_task = next_task
ldr r0, [r3, r4, lsl #2]// load PSP value from PSP_array
ldmia r0!, {r4-r11} // load R4-R11 from task stack
msr psp, r0 // set PSP to next task
bx lr // return
align 4
}
上图是对仿真结果的部分截图,从图中能看出 4 个任务在被调度执行。不过在编写程序中,遇到些插曲,最开始将 SysTick_Handler 最后的 SCB->ICSR |= SCB_ICSR_PENDSVSET_Msk 写为 SCB->ICSR |= SCB_ICSR_PENDSTSET_Msk 导致一直在 SysTick_Handler 中出不来,经查阅 PENDSTSET 是将 SysTick 挂起,可能导致挂起后又立即执行无限循环。看来有时候自动补全还会坑人😄
接下来对程序一些部分进行解释说明
/* 让 PSP_array[0] 指向任务栈栈顶,然后再向下开出 64 字节栈空间 */
PSP_array[0] = ((unsigned int)task0_stack) + (sizeof task0_stack) - 16 * 4;
/* 向 PSP_array[0]+56 的地址写 4 字节数据(任务函数入口地址) */
HW32_REG((PSP_array[0] + (14 << 2))) = (unsigned long)task0;
/* 向 PSP_array[0]+60 的地址写 4 字节数据(xPSR:0x0100_0000) */
HW32_REG((PSP_array[0] + (15 << 2))) = 0x01000000;
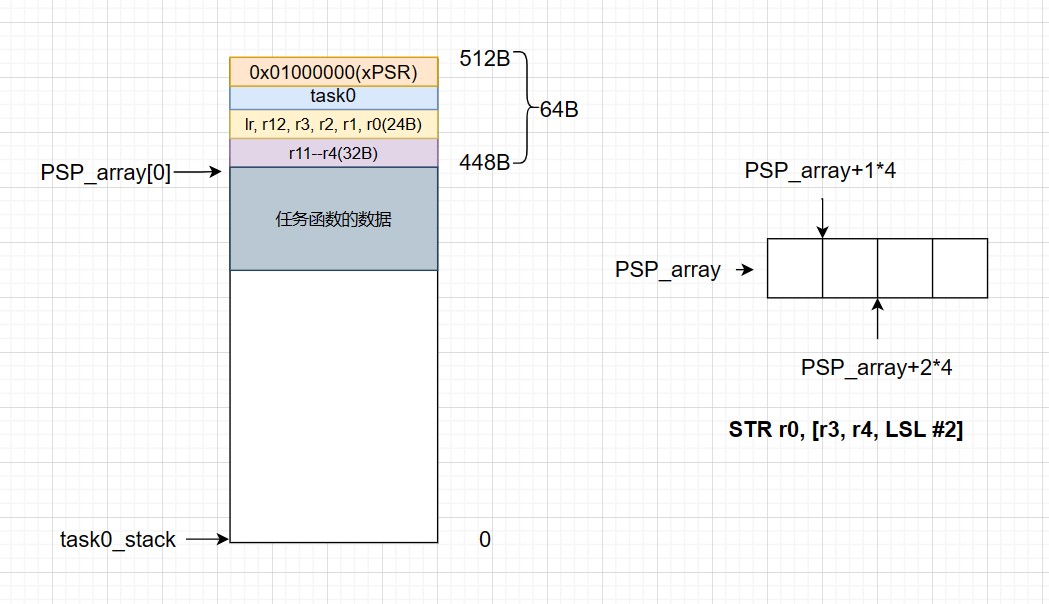
/* 让 PSP 重新指回任务栈顶 */
__set_PSP((PSP_array[curr_task] + 16*4));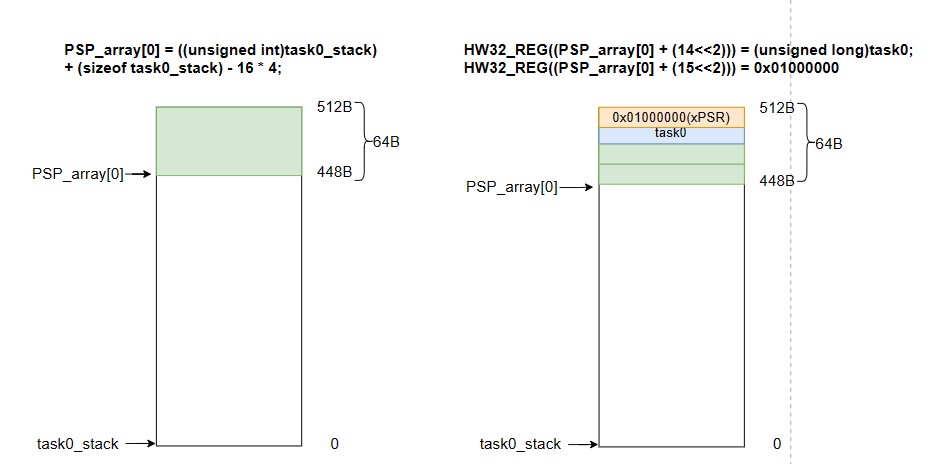
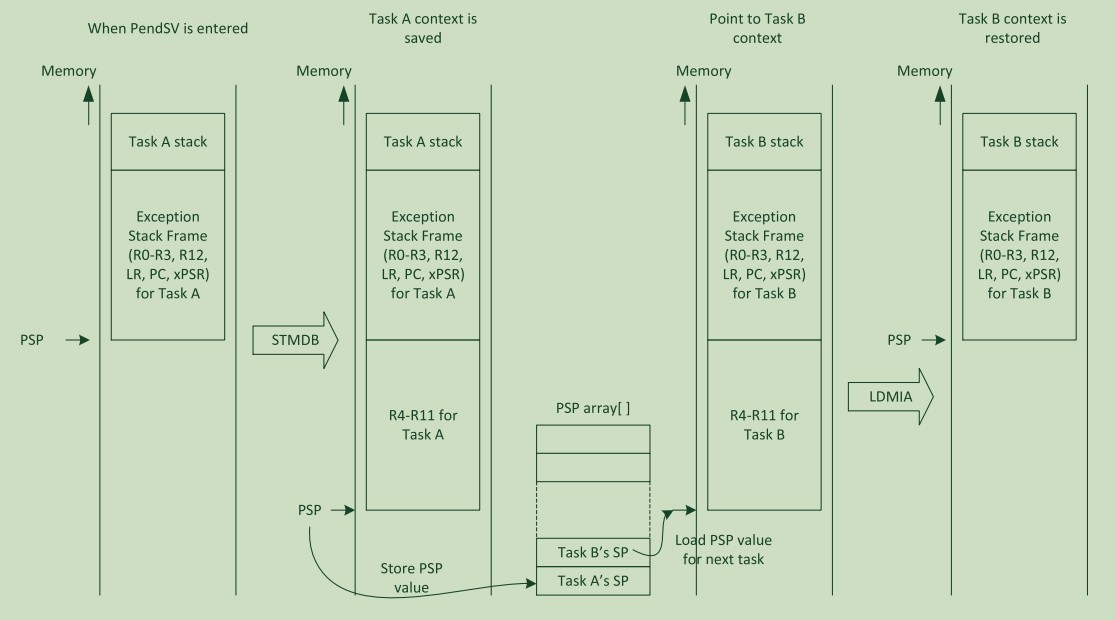
/* 在进入 PendSV_Handler 之前,系统已自动将 lr,r12,r3,r2,r1,r0 压栈 */
// 手动将当前任务数据压栈
mrs r0, psp // 将自动压栈后的 SP 赋给 r0
stmdb r0!, {r4-r11} // 通过 r0 手动将 r4-r11 接着压栈
ldr r1, =__cpp(&curr_task)
ldr r2, [r1] // 将当前任务的 ID 存到 r2
ldr r3, =__cpp(&PSP_array)
str r0, [r3, r2, lsl #2]// 将手动压栈后的栈顶值存到 PSP_array 对应任务的元素中
/* [r3, r2, lsl #2]: 先将 r2 值左移 2 位,其结果再与 r3 相加,再将 r0 作其数据
* 其实就是根据 PSP_array + taskID*4 找到对应任务栈顶要存放的地址 */
// 准备下个任务的数据(出栈)
ldr r4, =__cpp(&next_task)
ldr r4, [r4] // 获取下个任务 ID 存入 r4
str r4, [r1] // 将下个任务设置为当前任务
ldr r0, [r3, r4, lsl #2]// 获取当前任务栈顶值并存到 r0
ldmia r0!, {r4-r11} // 用 r0 手动出栈 r4-r11
msr psp, r0 // 将出栈后栈顶值交给 PSP
bx lr // 返回退出
整个任务切换的过程图如下:
至此,ARM Cortex-M 的基本知识点就结束,虽然还有未涉及到的知识,但这些基础知识已经让我对 ARM 结构有了初步认识,后面的只需在此之上扩展即可。特别是最后的 OS 异常,让我对之前学的 FreeRTOS 任务切换过程更加清晰明了