C_Grammar_JJZ
记录 C 语言指针、结构体等较高阶的知识
学习笔记,仅供参考
参考:程序员的 C - B站氿酱紫 | 视频对应博客
C 语言指针之前的部分:变量、函数、条件、循环等属于程序逻辑部分,在任何语言中都能见到;而像指针、结构体等知识则并非如此,并且这些特性在开发中也很实用,故记录基础的定义和使用
指针和数组
指针:指向某个变量,即指针变量保存的是所指向变量的地址。且指针变量的大小总是 8 字节(32位),而其所指向变量的类型只影响它在内存寻址时步距的大小。如 char *p 步距为 1 字节;int *p 步距为 4 字节
数组:一组同类型的变量的集合,在内存中 back-to-back 连续存储。数组名并非指针,它只是数组首地址的一种别称。
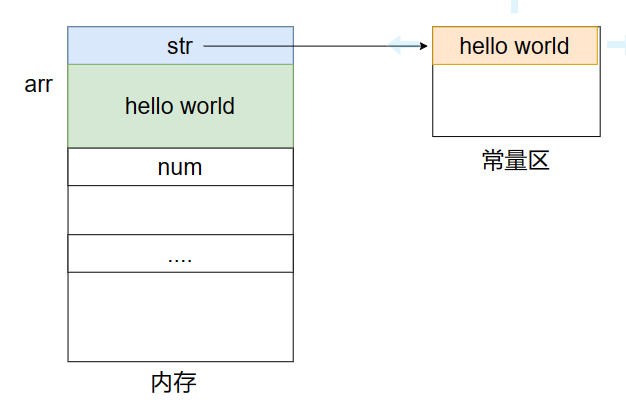
字符数组与字符指针:下面代码分别用数组和指针来创建字符串,看看它们的区别
char *str = "hello world";
char arr[20] = "hello world";
int num = 0;字符数组是在内存中开辟 20 字节的空间存放字符,即 arr[0] = ‘x’ 可更换元素;而字符指针指向常量区所开辟的空间,因为常量区为使字面量复用,即 str[0] = ‘x’ 会出错
结构体
结构体:一种自定义能包含多种类型的数据结构,并且支持结构嵌套(一个结构含有另一结构的指针变量-模拟父类继承)。结构在函数中可有两种方式传递数据:结构传递、结构地址传递,多数会选用结构地址传递,只需传递地址执行快但无法保护数据,不过 ANSI C 提供了 const 修饰符可解决此问题。
/* 结构体声明、定义、初始化 */
struct student {
char *id;
char *name;
int age;
};
struct student s1 = {0}; // 零值初始化
struct student s2 = {"A001", "Tom", 18}; // 顺序初始化
struct student s3 = {.name="Jerry", .id="A002"}; // 使用初始化器(C99)
// 由于声明定义时都要带上标记符,麻烦可用 typedef 简化
typedef struct {
char *id;
char *name;
int age;
} Student;
Student s1 = {0};结构体中存放字符串时仍有字符数组和字符指针两种方式,字符数组简单理解,而字符指针在获取 scanf 输入时会有隐患,因为字符指针在未初始化时值是不确定的
struct pnames attorney;
puts("Enter the last name of your attorney:");
scanf("%s", attorney.last);伸缩型数组成员(flexible array member):C99 新增特性,声明一个伸缩数组成员有以下规则:伸缩型数组成员必须是结构的最后一个成员;结构中必须至少有一个成员;声明类似普通数组只是方括号中为空。
/* 伸缩型数组成员声明、定义、分配空间 */
struct flex {
size_t count;
double average;
double scores[]; // 伸缩型数组成员
};
struct flex *pf;
pf = malloc(sizeof(struct flex) + n*sizeof(double));内存对齐
// 1. 第一种排列方式
struct A { int a; char b; short c; }
struct A struA = {0};
sizeof(struA);
/* 8 byte
|x|x|x|x|
|x|x|x| | */
// 2. 第二种排列方式
struct A { char b; int a; short c; }
sizeof(struA);
/* 12 byte
|x| | | |
|x|x|x|x|
|x|x| | | */为节省时间计算机往往不会以 1 字节取放数据,而是以字长(4字节-32位机;8字节-64位机)存放数据,下面是两中排列方式对应计算机的存取过程
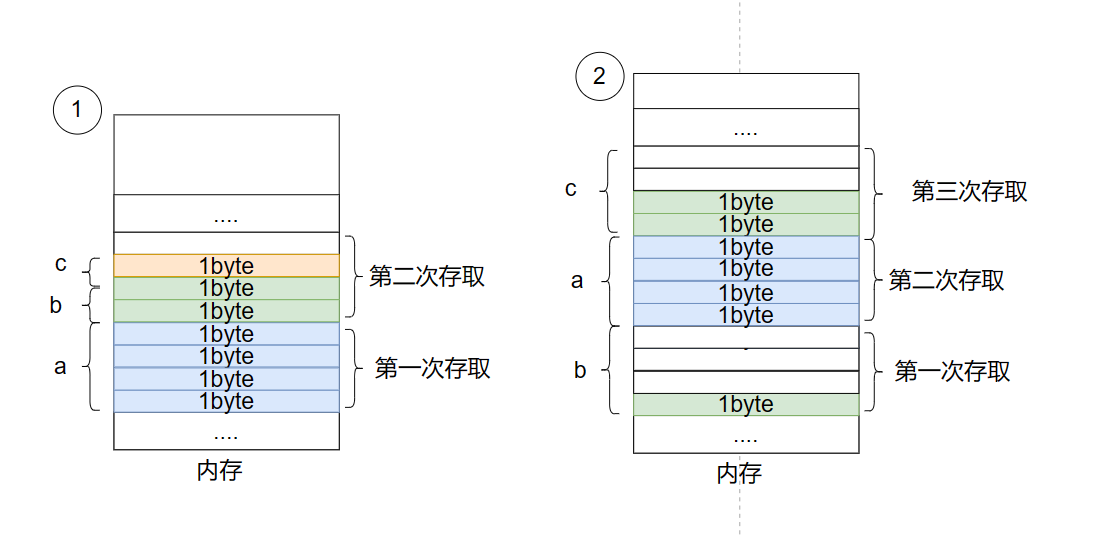
为何不将上图②中 a 变量紧接着 b 存储呢?这是出于时间与空间的取舍,当要从内存中取 a、b 变量的值时,第一次取 4 字节得到 b 变量值;第二次依旧取第一次的 4 字节得到 a 变量的部分值;第三次取下一个 4 字节得到 a 变量另外的部分值;所以要花三步取值命令才能得到 a、b 变量。而照着 ② 图只需两次就能得到 a、b 变量值
// 取消编译器的内存对齐
#progma pack(1)
struct A { int a; char b; short c; };
sizeof(struA); // 7 bytes(变量紧密相连无空间浪费)
#progma pack()枚举
// 定义
enum Week { MON, TUE, WED, THU, FRI, SAT, SUN };
// 默认首元素值为 0,后续依次加 1
enum Week { MON=1, TUE, ... }
// 指定首元素值为 1,后续仍依次加 1
头文件与预处理
#include <stdio.h>
#include "utils.h"
// 常常会用 <>, "" 来引用头文件,它们的区别如下:
1. 当 .c 和 .h 放在同一目录下时,是以 .c 源文件路径为参照进行文件查找,故用 "" 包含
2. 当 .c 和 .h 不在同一目录下时,且已指定 .h 的路径可用 <> 或 "" 包含
// 两种指定 .h 路径的方法
1. 使用 gcc -I[绝对路径]
gcc t1.c t2.c main.c -o main -ID:\workspace\head
2. 设置环境变量(以 linux 为例)
set C_INCLUDE_PATH=D:\workspace\head拓展:头文件规则
预处理 可分为如下三类:
文件包含:#include 将所包含的头文件复制黏贴到该文件中
宏定义:#define 在预编译阶段进行字符串替换
条件编译:#if, #ifdef, #ifndef 跨平台处理,多环境
另外,#include、#define 并非 C 的语法,属于编译器做的仅是 CV 操作
// C 语言编译成可执行文件的四个阶段:预编译-->编译-->汇编-->链接
gcc -E main.c -o main.i // gcc 预编译,复制头文件替换宏定义
gcc -S main.i -o main.s // gcc 编译,将预编译后的 c 转为汇编文件
gcc -c mian.s -o main.o // gcc 汇编,将汇编文件转为二进制 object 文件
gcc main.o -o main // 由于 gcc 将 ld 打包,此处直接用 gcc 将引用的 io 文件链接到一起
宏定义
1. 普通宏
#define PI 3.1415926
2. 带参宏(并非函数)
#define MAX(a, b) ((a)>(b)?(a):(b))
// 给形参 a、b 加上括号防止出错
宏定义的两个专用运算符 # 和 ##
- # 用来字符串化宏函数里的参数
#define PRINT_INT(n) printf(#n "=%d\n", n)
PRINT_INT(i/j); --> 替换后:printf("i/j""=%d\n", i/j);
--> 等价于:printf("i/j=%d\n", i/j);
- ## 可将两个记号粘合在一起
#define GENERIC_MAX(type) \ // 使用 \ 做连接符
type type##_max(type x, type y) {\
return x > y ? x : y;}
GENERIC_MAX(int) --> 替换后:
int int_max(int x, int y) { return x>y?x:y; }
// 类似于泛型,根据 type 的不同能生成不同的 MAX 函数
3. 创建包含多条语句的宏 - 使用 do-while 来规避各种语法错误
【定义】
#define ECHO(s) \
do {
gets(s);\
puts(s);\
} while(0)
【使用】
ECHO(str); --> 替换后:
do { gets(str); puts(str);
} while(0);
4. 预定义宏 - 编译器预先定义好的宏
_LINE_:当前行号 | _FILE_:当前源文件名
_DATE_:编译日期(MM-dd-yyyy) | _TIME_:编译时间(hh:mm:ss)
// 这些预定义宏可用于 log 日志,给出一些信息
总结:
宏函数减少函数栈的调用,提升点性能,缺点是展开后增加体积
参数无类型检查,缺少安全机制
宏可进行多层嵌套替换
宏作用域存在至包含其 .c 文件的末尾
宏不可定义两次,需用 #undef 取消宏
内存管理&内存分配
内存四区:栈(自动申请&释放,局部作用域),堆(手动申请&释放,作用域受接收指针限制),静态/全局区(自动申请&释放,文件作用域),代码区
为何要在堆上分配动态内存?
栈区内存通常比较小,具体视编译器而定,通常可能会在 2M 大小左右,当需处理大文件、图片、视频等数据时,2M 显然不够这就需更大的内存空间。而堆内存是没有限制的,只要内存条足够大就能申请到足够大的堆内存使用
栈内存的使用有一定的特殊性,通常当函数调用结束后就会出栈,此时那些函数中的局部变量就不存在了,所以若想要一个变量有更长的生命周期,堆内存是更好的选择
全局变量虽与程序有着相同的生命周期,但无法动态地确定大小
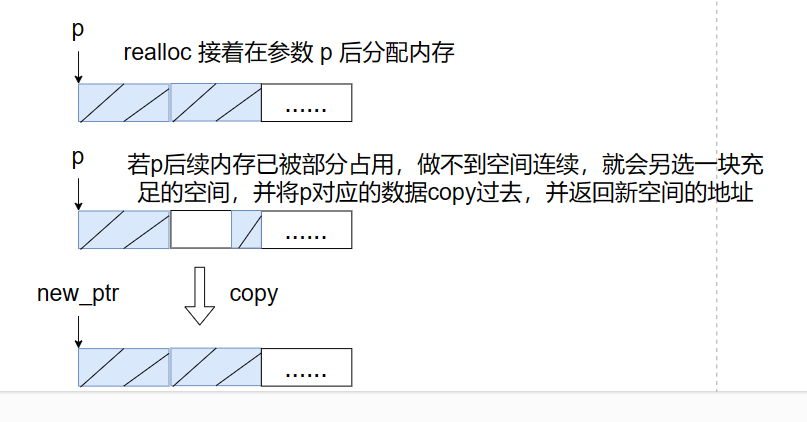
// 三种动态分配的函数 // 1. malloc 分配,返回无类型指针,接收时要强转类型,且申请内存后要手动释放 // 当 malloc 分配失败时会返回 NULL,可用 memset() 初始化所分配的内存 void *malloc(size_t size); int *p = (int *)malloc(n*sizeof(int)); // 开辟 n 个 int 型内存空间 free(p); p = NULL; // 手动释放内存,并将 p 指向 NULL,防止出错 // 2. 使用 calloc 分配,在分配后会进行零值初始化 // 分配空间的大小 = num * sizeofElem void *calloc(size_t num, size_t sizeofElem); // 3. 使用 realloc 重新分配内存,可对已分配的内存扩充缩减 // p 指所要重新分配内存的地址,size 为重新分配内存的大小 // 当 size 大于原空间时,为扩充内存;小于原空间时,为缩减空间 void *realloc(void *p, size_t size); // 注意 realloc 返回的指针不一定与接收的指针指向同一地址内存 // 当扩容空间足够时,return ptr == receive ptr // 当扩容空间不够时,return ptr != receive ptr char *pchar = (char *)realloc(NULL, sizeof(char)*10); // 等价于 malloc 分配 realloc(pchar, 0); // 等价于 free 释放内存
接着看看开头的内存四区是如何在内存中分布的
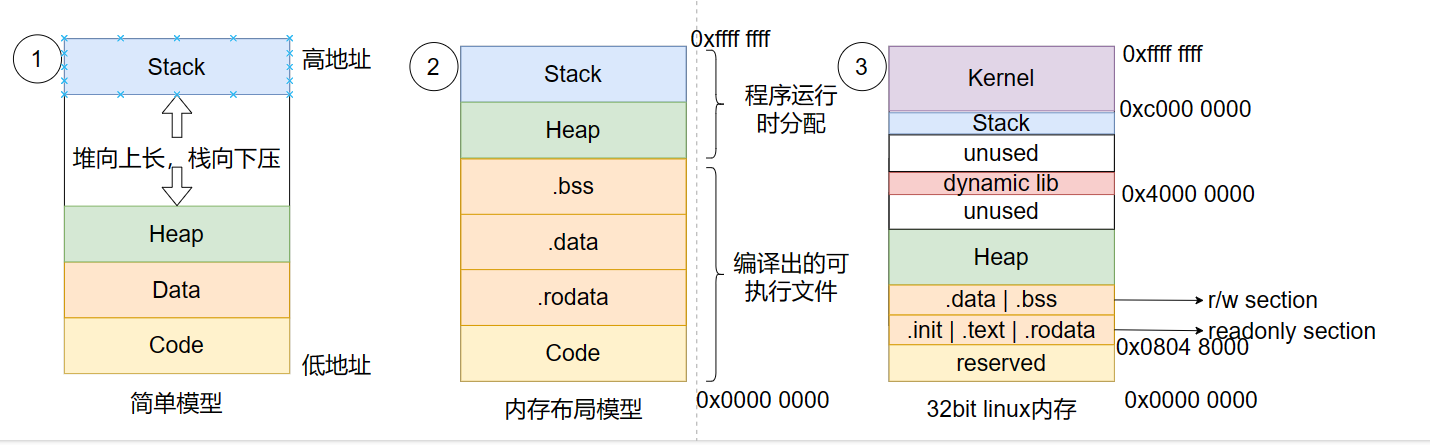
Stack:由编译器自动分配&释放,存放函数的参数、局部变量、返回值等,后进先出,向下拓展
Heap:程序运行中分配,由程序员手动分配&释放,大小不固定可动态扩缩
Data:含静态/全局变量,可大致分为 .bss(未初始化)、.data(初始化)
.bss:block started by symbol,存放未初始化的静态/全局变量,在 main 之前内核将这部分 data 做零值初始化
.data:存放已初始化的静态/全局变量,data 值可变
.rodata:read-only 只读数据段,存放 const 修饰的常量、字符串字面量,编译器会去重,仅保留一份常量节省空间
Code:代码段,存放 cpu 要执行的机器指令,只读
指针&数组拓展
二维数组遍历:
下标法:使用双重 for 循环遍历,模型为二维方格
指针法:使用首位指针遍历,模型为一位方格
int table[2][3] = { {1, 3, 5}, {2, 4, 6} }; int *start = table; int *end = &table[1][2]; for (; start <= end; start++) { printf("%d\n", *start); }
逗号运算符:逗号运算符最终将以最右边的值为主
int n = (1, 2, 3); // n=3
int a[3][2] = { (0, 1), (2, 3), (4, 5) };
/*
a --> | 1 | 3 |
| 5 | 0 |
| 0 | 0 |
*/二级指针:可指向字符串数组,char **p;(一级指针修改所指内存的值,二级指针修改一级指针所指向的内存地址)
// 用 typedef 定义数组类型
typedef int(MyArray)[10]; // 定义大小为 10 的 int 数组类型
MyArray myArray;
myArray[0] = 8;指针数组:所有元素均为指针的数组,形式:dataType *arrName[len]; 例:char *arr[3]; 定义字符串数组
数组指针:指向数组的指针,亦称*行指针。形式:dataType (*arrName)[len]; 例:int (*arr)[4]; (注:圆括号不可省,[]优先级高于 *)该例子指定义了一个指针 arr,arr 移动的步长为 4 个整型大小
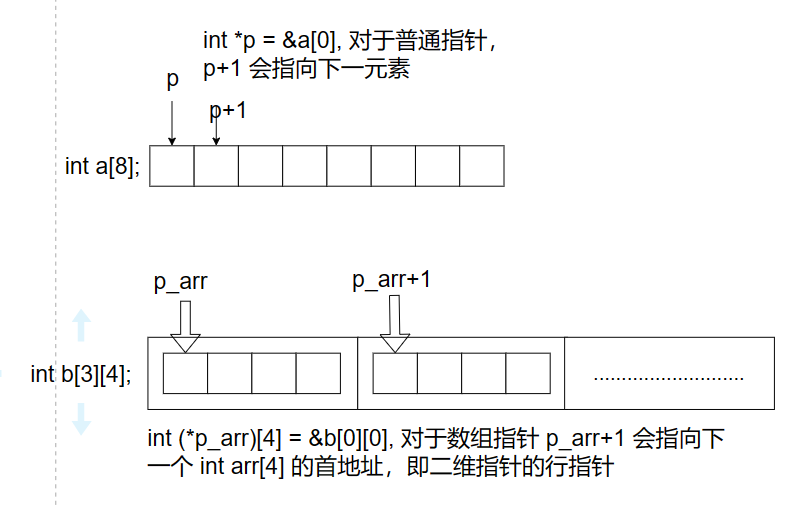
函数指针& void 指针
函数指针:保存函数起始地址的指针变量,形式:[返回值类型](*p)(形参类型, ...)
int (*p)(int, int); // 函数指针声明
p = add; // 初始化
p(1, 3); // 调用
int (*p)(int, int) = add; // 声明并初始化
/* 函数指针的传递 */
// 计算器函数,将函数指针做形参
void calculate(int a, int b, int(*proc)(int, int)) {
printf("result = %d\n", proc(a, b));
}
int main(void) {
calculate(10, 5, add); // 加法
calculate(10, 5, sub); // 减法
return 0;
}
// 将函数指针作为参数传递使得 C 语言变得更加灵活强大。
// 而在 python、JS 等编程语言中,当前流行的函数式编程范式,
// 即将一个函数作为参数传到另一函数中执行
/* 利用 typedef 简化函数指针声明 */
// 类似数组类型的定义,无需起别名
typedef int(*proc)(int, int);
// 简化声明
void calculate(int a, int b, proc p) {
printf("result = %d\n", p(a, b));
}
/* 函数指针模拟 oop 的类 */
struct Class {
char *id; // 属性/字段
char *name;
int age;
int (*method)(int, int); // 行为/方法
}void 指针:通用指针,可指向任意类型,但其无类型检查需谨慎使用
short num = 10;
char *p_char = (char *)#
int *p_int = (int *)#
// p_char, p_int 指向地址相同,但解引用的值不同
// *p_char = 10 | *p_int = -29491128
// 由此,指针用来保存变量的地址,与其类型无关,
// 任意类型指针都可保存任意地址,而类型仅与解引用有关
/* 使用 void * 模拟泛型 */
void swap(void *a, void *b, int size) {
// 申请一定大小的堆空间
void *tmp = (void *)malloc(size);
memcpy(tmp, a, size); // swap data
memcpy(a, b, size);
memcpy(b, tmp, size);
free(tmp); // 释放内存
}
swap(&a, &b, sizeof(int)); // int 类型
swap(&a, &b, sizeof(long)); // long 类型
函数指针实用小结:
利用函数指针可实现函数式编程
将函数指针存入数组中,可实现函数回调通知机制
将结构体于函数指针结合,可模拟 OOP 中的类,实际上 GO 语言就是如此
链接与库
这里仅是对视频内容做简要笔记,更多相关知识可参考书籍《程序员的自我修养-编译链接与库》, 《CSAPP》- 第七章链接
虚拟内存
在早起计算机系统中,程序可直接操作物理内存,即实模式。如可用 C 语言向某个内存地址中写入数据,但如此一来就会带来无法避免的问题。比如,程序 A 中占用了大部分内存,若再想运行程序 B 就会内存不足,因此早起系统是单任务的,同一时间无法运行多个程序。
随着多任务系统的出现,可同时运行多个程序,也带来新问题,如内存重叠、内存冲突。假如两个程序都用到同一块内存,当它们同时运行时就会造成冲突,程序在编译时永远无法确定哪块内存是没有被人使用的。为此 OS 出现了虚拟内存的概念
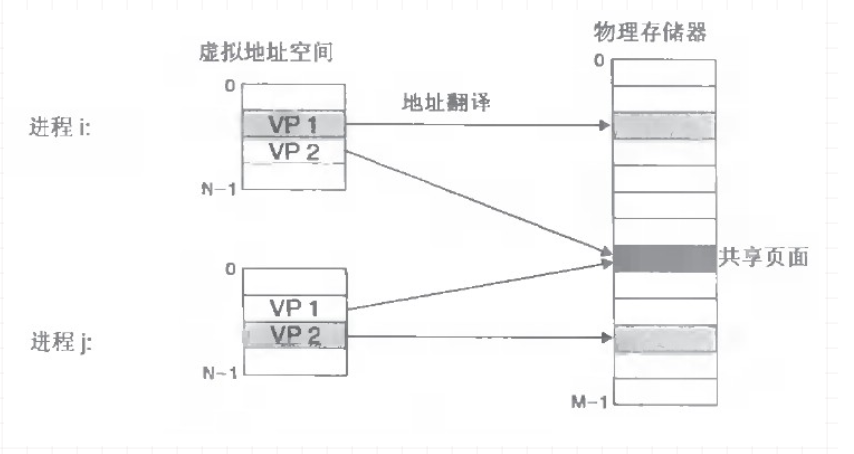
所谓虚拟内存,就是一张地址转换表,程序不能直接操作物理内存,只能操作这张转换表。并且为提高此表的查找效率,采用分页的方式,因此此表也称为页表
程序实际上操作的是页表中的虚拟地址,而页表再将其映射到物理内存地址。如此程序就不用再关注物理内存了,对程序而言它的一切操作都是对虚拟内存地址进行的,由 OS 在底层再去转为真正的物理内存地址。这样做的好处:
避免地址冲突,即使两个程序操作同一地址也不会冲突了,因为每个程序都有对应的虚拟地址,底层对应到不同的物理地址
控制访问权限,通过虚拟地址将程序与物理地址隔开,即使程序非法访问到其他的内存地址,OS 在页表这关将其拦截掉,不会造成物理地址的访问,从而保证程序的安全性
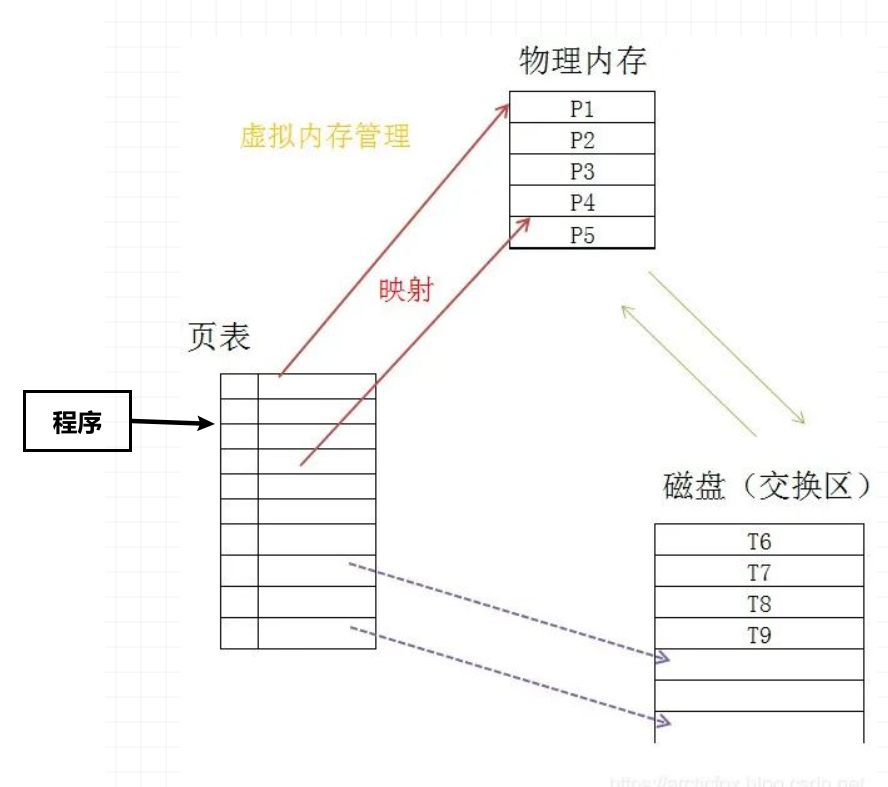
在装 Linux 系统时要设置交换区大小,而交换区就是在磁盘上开辟一个固定空间,通常就是在硬盘上,这样就能将不常用到的程序所占用的内存移到此交换区中,目的就是缓解内存资源更加高效的使用
关于交换区访问,如上图若在页表中访问 T6 的地址,发现页表中没有,即缺页,那么系统就会启动对应的处理程序。简单说就是将物理内存中不活跃的内存(如P5)移到交换区中,腾出的P5空间再交给交换区移出的 T6,然后更新页表,如此就发生物理内存与交换区内容的交换,之后程序就能正常访问到 T6 的数据
通过交换区可让所能使用的内存超过物理内存,但交换区也不能太大,因为硬盘的访问速度要比内存慢 500 多倍,若将数据大量存放到交换区中,就会拖慢程序运行的速度
链接
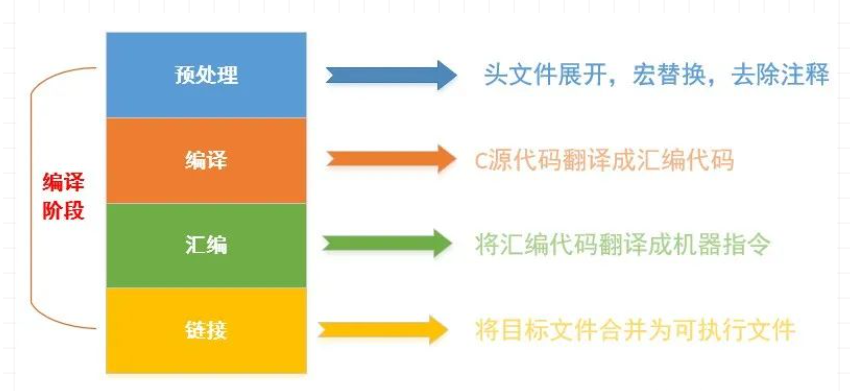
链接,指将多个目标文件合并成一个可执行文件的过程。再回顾下编译的四个阶段:预编译–>编译–>汇编–>链接
/* 以 Windows 下 MinGW 的 gcc 为例 */
1. CPP(C Pre-Processor),位与 MinGW 的 bin 下
cmd: cpp main.c -o main.i --->
对应 gcc: gcc -E main.c -o main.i
2. 编译器(cc1),位与 MinGW/libexe/gcc/ 下
cmd: cc1 main.i -o main.s --->
对应 gcc: gcc -S mian.i -o main.s
3. 汇编器(as),位与 MinGW/bin 下
cmd: as main.s -o main.o --->
对应 gcc: gcc -c main.s -o main.o
4. 连接器(ld),位与 MinGW/bin 下
cmd: ld calc.o main.o -e start -o main.exe --->
对应 gcc: gcc calc.o main.o -o main
// ld 的 -e 指定程序入口函数为 start 函数,因为 C 语言并未规定 main 函数
// 作为入口函数,而 gcc 在链接时实际用的是 collect2 库来处理链接,
// 它会调用各种初始化函数,并用 libgcc 设置 __main 符号,从而让 main 作为入口函数。
// 实际上在汇编程序中,真正的入口函数是 _start,因此这里用 start 作为入口函数
链接:将多个不同的目标文件合并到一起,目标文件间的相互引用就是文件间对地址的引用,即函数和变量地址的引用。在链接中,函数和变量统称为符号(symbol),函数名和变量名称符号名(symbol name)
链接的关键就是对符号进行管理,每个 object 文件都有相应记录所有符号的符号表,每个符号有一个值,即符号值(symbol value),对于函数和变量符号值就是它们的地址
简单理解,符号在汇编中代表一个地址,经汇编器处理后,所有的符号都会被替换成它所代表的地址值。C 中是通过变量名访问该变量,即读写某个地址的内存空间;通过函数名调用此函数,即跳转到该函数第一条指令所在地址,故变量名和函数名均是符号,本质上就代表内存地址
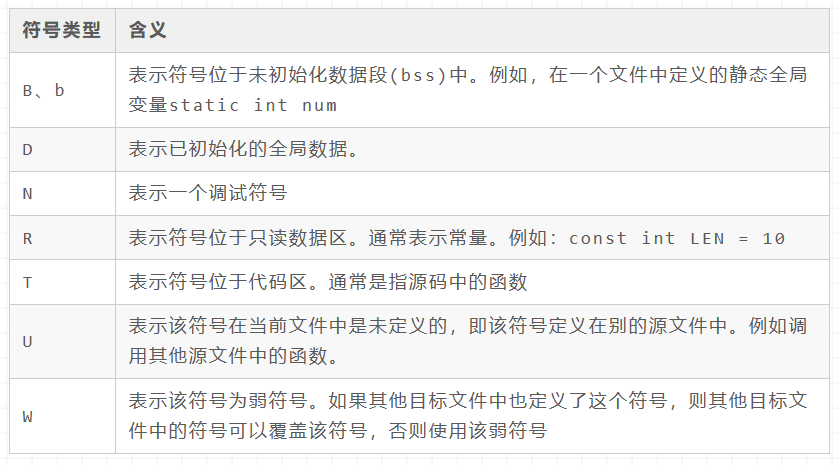
查看符号表:可用 GNU GCC 提供的工具链 nm 命令查看目标文件的符号表。nm calc.o, nm main.o 查看目标文件,nm main.exe 查看可执行文件。经验证会发现 main.exe 的符号表就是 calc.o main.o 合并而成的;或用 objdump 命令objdump -t calc.o, `objdump -t main.o
可通过下面符号类型表理解 nm 命令结果对应的含义
链接作用
符号解析,将符合引用与符号定义关联起来
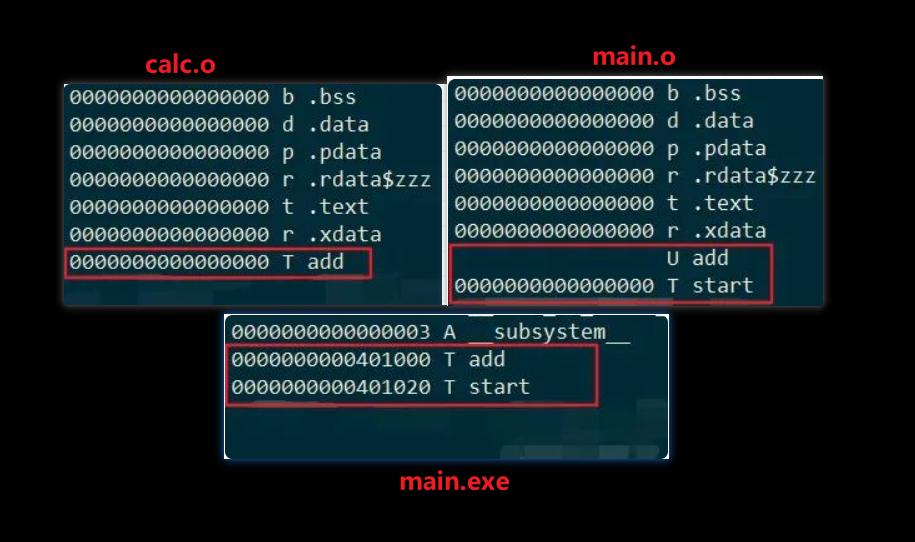
地址重定位,将合成后文件的符号地址重定位,分配一个真实有效的虚拟内存地址,如下图中所看到的 .o 文件的地址都是 0,而 .exe 就是实际有效的地址
链接分类
静态链接,将多个 object 文件的内容 copy 到一个 .exe 文件的链接方式(直观、简单)
动态链接,并非全 copy 的方式,灵活常用,但性能会低于静态链接
函数库:一个 object 文件的文件包,它包含静态库和动态库两种
/* 静态库 */
// 打包静态库 - ar 打包命令
ar rs libcalc.a add.o sub.o mul.o div.o
//【参数】r-为后面的 .o 文件创建文件包;s-用于生成静态库
// libcalc.a 为生成静态库的文件名,其中 lib 为前缀,.a 为文件后缀,calc 为库名
// 链接静态库
gcc main.o -L. -lcalc -o main.exe
// 【参数】-L 设置链接库路径,.表示当前目录(参数与路径间无空格)
// -l 后跟库名,无前后缀
/* 静态库优缺点:在链接时简单易理解,但当静态库文件有变动时就要
重新打包并重新链接生成新的 exe 文件,如此就麻烦许多 */
/*************************************************/
/* 动态库/共享库 */
// 生成与位置无关的 obj 文件
gcc -fPIC -c add.c sub.c mul.c div.c
// 【参数】-fPIC 表示生成位置无关代码
// 打包动态库
gcc -shared add.o sub.o mul.o div.o -o libcalc.dll
// 【参数】-shared 生成动态库;win 下以 .dll(dynamic linking library) 为动态库后缀
// 而 linux 下以 .so(shared object) 为后缀
// 上面两步的综合命令
gcc -fPIC -shared add.c sub.c mul.c div.c -o libcalc.dll
// 链接动态库-三种方式(实验时需先删除静态库以防止干扰)
1. gcc app.c libcalc.dll -o app // 直接关联
2. gcc app.c -L. -lcalc -o app // 指定路径与静态库的类似
3. 设置 LD_LIBRARY_PATH 环境变量
/* 动态库优缺点:解决更新库麻烦的问题,当修改完库文件后只需打包好库替换掉原来的即可,
不用再链接生成新的程序,该过程可通过网络程序从服务器下载库并自动替换
这种方式也称为热更新 */静态库与动态库的区别:实际就是静态链接与动态链接的区别
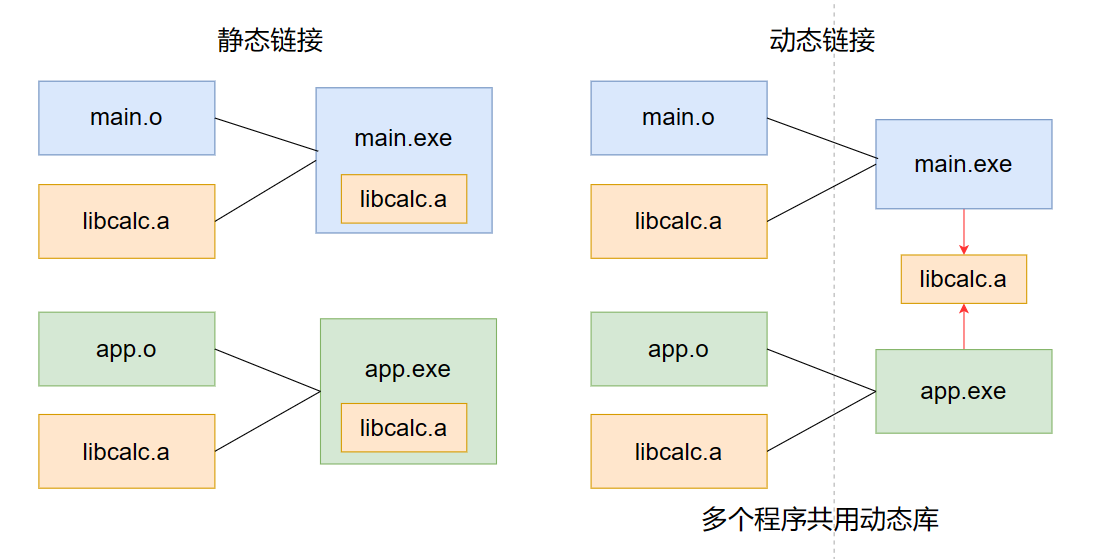
如上图,若多个程序使用同一静态库,会额外占用内存来存放各自程序下的 libcalc.a ,且静态库本身代码修改后所使用该库的程序都要重新编译发布;而对于动态链接中所有程序共用同一动态库,节省加载到内存的空间,在库修改时只需更新对应动态库即可,不用重新编译发布程序
动态链接
动态链接在程序链接阶段并未真正发生链接,只在该程序启动被装载到内存时才会发生真正链接。等于将本该在编译时发生的链接行为推迟到程序被启动时。
动态链接要比静态链接复杂的多,且概念易混淆,它可分为:
装载时动态链接
运行时动态链接(延迟绑定)
经过之前学习,链接往往指编译时链接,即编译过程的第四个阶段,经链接后方可生成可执行程序。事实上,编译时链接都是静态链接。动态链接并不能在编译时进行,它只能在加载时进行,且动态链接工作由一个叫动态链接器的东西来完成,而非 ld 命令
动态链接的思想就是把程序按照模块拆分成各个相对独立的部分,在程序运行时才将它们链接到一起形成一个完整程序,而非像静态链接那样把所有的程序模块都链接成一个单独的可执行文件
总结:
静态库
生成可执行文件体积大
任何修改都需重新编译发布,不利于更新维护
整个应用只由一个可执行文件构成
符号使用绝对地址,性能略高于动态库
动态库
生成可执行文件体积小
可热更新,方便修改维护
通常一个完整程序由一个可执行文件和多个动态库文件组成
动态库的调用需跳转,相比静态库性能略低,且不能脱离共享库文件
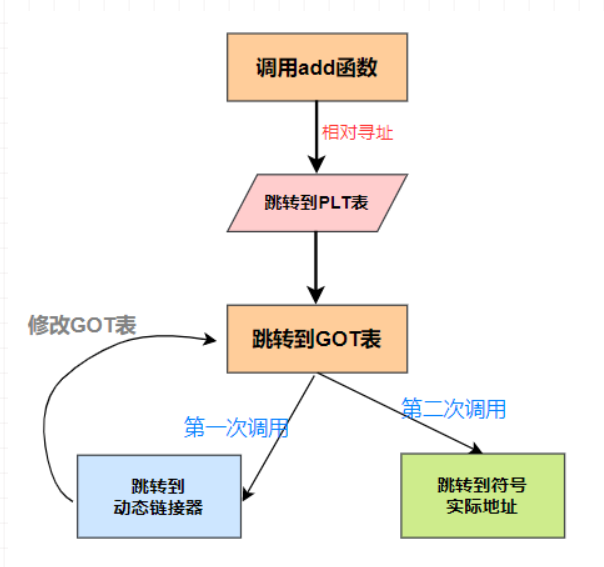
延时绑定技术,指在真正需要运行该函数时,才会去加载该函数所在的动态库,所以亦可称为运行时加载或显式加载。有了延时绑定技术可让 C 语言实现强大的框架功能,程序不用停止就能在运行时动态地给它增加或切换新功能,这种技术也称插件技术
下面是动态链接延时绑定的过程
文件 IO
C 将文件看作是一系列连续的字节,每个字节都能被单独读取。这与 Unix 中的文件结构对应,而对于其他系统就不一定对应,所以 C 提供了两种文件模式:文本模式 和 二进制模式
所有文件的内容都以 0/1 形式存储,但若文件最初使用二进制编码的字符(ASCII/Unicode)表示文本,那该文件就是文本文件;若文件中的二进制值代表机器码、数值数据、图片或音乐编码等,那该文件就是二进制文件
在二进制模式中,程序可访问文件的每个字节;而文本模式中程序所见的内容和文件的实际内容不同。程序以文本模式读写文件时,会将本地环境表示的航模为或文件末尾映射为 C 模式。
标准 IO:包含了许多专门的函数以简化处理 IO 的问题;且输入和输出都是缓冲的,即一次转移一大块信息而非一字节,缓冲区提高了数据传输速率
fopen(char *Filename, char *Mode)打开文件函数,第一个参数为要打开文件的文件名;第二个参数为打开的模式(读/写)

像 Linux 这种只有一种文件类型的 OS,带 b 与不带 b 的模式相同。注意:在 w 写模式下,会先将文件清空
getc(FILE *file)从指定文件中读取一个字符;putc(char ch, FILE *file)将 ch 字符写到指定文件中;gets、puts读写字符串,与字符类似
fclose(FILE *file)关闭指定文件
文件 IO 接口
格式化输出
printf(format, …) // 写入到标准输出流
fprintf(file, format, …) // 写入指定文件中
*sprintf(char *buf, format, …)* // 写入指定缓存 buffer 中
*snprintf(char *buf, size, format, …)* // 写入最大 size 个字节到指定缓存 buffer 中
格式化输入
scanf(format, …) // 从标准输入中读取数据
fscanf(file, format, …) // 冲指定文件中读取数据
*sscanf(char *buf, format, …)* // 从指定缓存 buffer 中读取数据
注:在 C11 中提供了上面标准输入的安全版本,即新函数都带有 _s 后缀(如:fscanf_s()),新函数在读入字符串到数组前会检查是否超出数组边界
文件读写
fread(buf, size, n, fp) // 从 fp 的流中读取最多 n 个对象,对象的空间大小为 size,并将读取到的对象数据存入 buf 中
fwrite(buf, size, n, fp) // 将 buf 数组中的 n 个大小为 size 的对象数据写入 fp 的流中
fflush(fp) // 刷新缓冲区
文件随机访问
long ftell(fp) // 获取当前文件指示符的位置
int fseek(fp, offset, origin) // orifin 确定起始点,offset 依据起始点做左右偏移
其他操作
*remove(char *filename)* // 删除文件
*rename(char *filename)* // 修改文件名